

linux基础教程之正则表达式小白读本
概念
正则表达式是对字符串操作的一种逻辑表达方式,很多情况下我们需要在茫众多的文件中找到我们需要的文件时,就需要用到正则表达式了
正则表达式就如同一个过滤器,能够筛选出希望得到的字符串。它可以检索、替换符合我们自己规定格式的所有文本。
- 正则表达式分两类:
- 基本正则表达式
-
扩展正则表达式
正则表达式的用法和选项
在Linux中,正则表达式通常会配合文本过滤工具grep使用。
- grep的功能强大,且简单粗暴。

以/etc目录为例
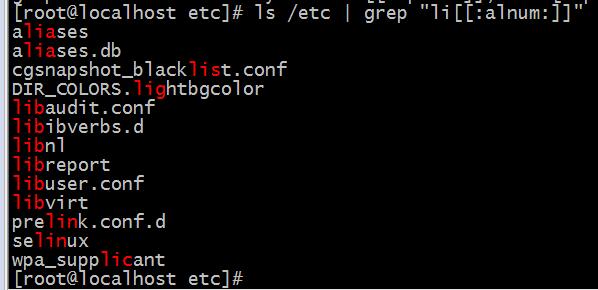
我们用grep来筛选一下其中含有”li”的文件
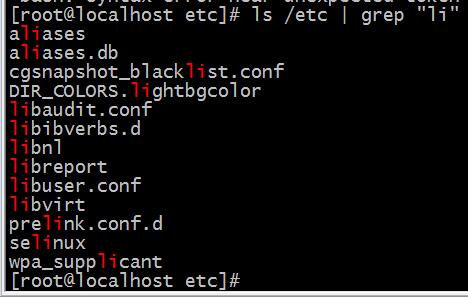
这是利用grep在/etc中对字母”li”进行筛选
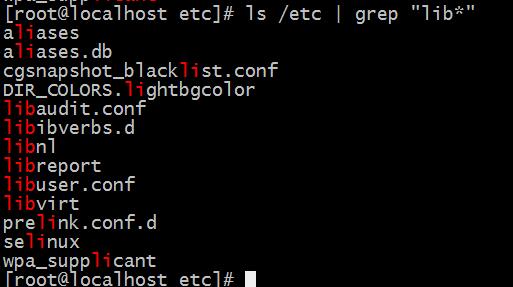
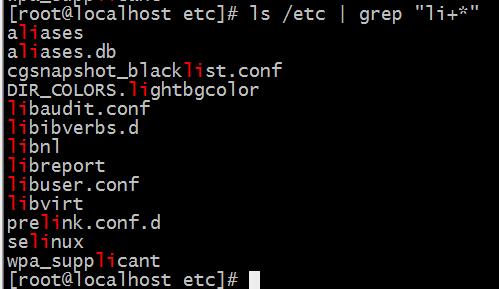
如果我们只想要以”li”为首字母的文件要怎么做呢?
这就需要用到正则表达式了
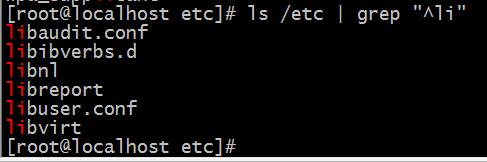
可以看到依靠正则表达式能很轻松的达到我们想要的结果。
正则表达式还有更多更强大的功能,让我们来了解一下吧。
- 正则表达式
正则表达式的元字符分类:匹配字符、匹配字数、位置锚定、分组-
- 字符匹配:
匹配任意单个字符 [] 匹配指定范围内的任意单个字符 [^] 匹配指定范围外的任意单个字符 [[:alnum:]] 字母和数字 [[:alpha:]] 代表任何英文大小写字符,亦即 A-Z, a-z [[:lower:]] 小写字母 [[:upper:]] 大写字母 [[:blank:]] 空白字符(空格和制表符) [[:digit:]] 十进制数字 [[:xdigit:]] 十六进制数字 [[:graph:]] 可打印的非空白字符 [[:print:]] 可打印字符 [[:punct:]] 标点符号
- 字符匹配:
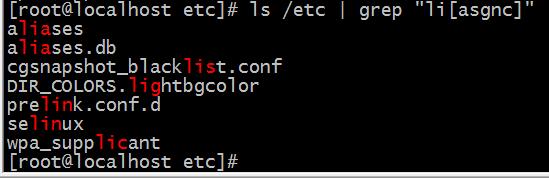
-
- 匹配字数(””为转译符,防止系统将某些字符当命令处理)
* 匹配前面的字符任意次,包括0次 + 匹配前面的字符1次以上,不包括0次 *? 匹配前面任意次,但尽可能少重复 .* 任意长度的任意字符 ? 匹配其前面的字符0或1次 + 匹配其前面的字符至少1次 {n} 匹配前面的字符n次 {m,n} 匹配前面的字符至少m次,至多n次 {,n} 匹配前面的字符至多n次 {n,} 匹配前面的字符至少n次
- 匹配字数(””为转译符,防止系统将某些字符当命令处理)
-
- 位置锚定 :
^ 行首锚定,用于模式的最左侧 $ 行尾锚定,用于模式的最右侧 < 或 b 词首锚定,用于单词模式的左侧 > 或 b 词尾锚定;用于单词模式的右侧 <PATTERN> 匹配整个单词
- 分组
分组 : () 将一个或多个字符捆绑在一起,当作一个整体进行处理,如 : (root)+
后向引用 : 引用前面的分组括号中的模式所匹配字符,而非模式本身
或者 : |
- 位置锚定 :

-
- 扩展正则表达式
扩展正则表达式是正则表达式的优化版,元字符的表达更简洁,更方便。
在grep中需要加选项 “-e” 来启用扩展正则表达式或egrep(=grep -e)- 在字符匹配中的双中括号在扩展正则表达式中可以简写为一个
[ : alnum : ] 字母和数字 [ : alpha : ] 代表任何英文大小写字符,亦即 A-Z, a-z [ : lower : ] 小写字母 [ : upper : ] 大写字母 [ : blank : ] 空白字符(空格和制表符) [ : digit : ] 十进制数字 [ : xdigit : ] 十六进制数字 [ : graph : ] 可打印的非空白字符 [ : print : ] 可打印字符 [ : punct : ] 标点符号
- 大部分转译符()可以省略 :
*: 匹配前面字符任意次 ? : 0或1次 +: 1次或多次 {m} : 匹配m次 {m,n} : 至少m,至多n次 a|b : a或b C|cat : C或cat (C|c)at : Cat或cat
- 在字符匹配中的双中括号在扩展正则表达式中可以简写为一个
总结
正则表达式的功能很强大且很好用,理解上也可能对于字符表达的含义会有些混乱需要多用多记才能熟练掌握。