

整整127页!这是一份阿里云内部超全K8s实战手册
一直关注云计算领域的人,必定知道Docker和Kubernetes的崛起。如今,世界范围内的公有云巨头(谷歌、亚马逊、微软、华为云、阿里云等等)都在其传统的公共云服务之上提供托管的Kubernetes服务。Kubernetes功能强大、扩展性高,在许多人看来,它正在成为云计算的终极解决方案。
接下来本文将为大家免费提供阿里云《深入浅出Kubernetes项目实战手册》下载,帮助你一次搞懂 6 个核心原理,吃透基础理论,一次学会 6 个典型问题的华丽操作!


如何免费下
扫描添加,发送"阿里云",即可免费获得

为何值得所有技术人收藏?
1.阿里云真实案例的沉淀
2.理论阐述深入浅出
3.理论和实践的完美契合
4.技术细节追根究底
本书作者罗建龙(花名声东),阿里云技术专家,有着多年操作系统和图形显卡驱动调试和开发经验。目前专注云原生领域,容器集群和服务网格。本书分为理论篇和实践篇,共汇集了 12 篇技术文章,深入解析了集群控制、集群伸缩原理、镜像拉取等理论,带你实现从基础概念的准确理解到上手实操的精准熟练,深入浅出使用 Kubernetes!
精彩分享:以下内容节选自《深入浅出 Kubernetes》一书
前言
阿里云有自己的 Kubernetes 容器集群产品。随着 Kubernetes 集群出货量的剧增,线上用户零星的发现,集群会非常低概率地出现节点 NotReady 情况。
据我们观察,这个问题差不多每个月就会有一到两个客户遇到。在节点 NotReady 之后,集群 Master 没有办法对这个节点做任何控制,比如下发新的 Pod,再比如抓取节点上正在运行 Pod 的实时信息。
在上面的问题中,我们的排查路径从 K8s 集群到容器运行时,再到 sdbus 和 systemd,不可谓不复杂。这个问题目前已经在 systemd 中做了修复,所以基本上能看到这个问题的几率是越来越低了。
但是,集群节点就绪问题还是有的,然而原因却有所不同。
今天这篇文章,将侧重和大家分享另外一例集群节点 NotReady 的问题。这个问题和上面问题相比,排查路径完全不同。
问题现象
这个问题的现象,也是集群节点会变成 NotReady 状态。问题可以通过重启节点暂时解决,但是在经过大概 20 天左右之后,问题会再次出现。
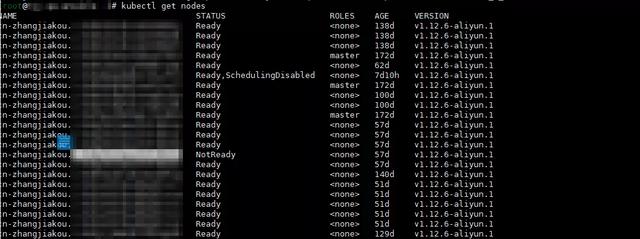
问题出现之后,如果我们重启节点上 kubelet,则节点会变成 Ready 状态,但这种状态只会持续三分钟。这是一个特别的情况。
大逻辑
在具体分析这个问题之前,我们先来看一下集群节点就绪状态背后的大逻辑。K8s 集群中,与节点就绪状态有关的组件,主要有四个,分别是:集群的核心数据库 etcd、集群的入口 API Server、节点控制器以及驻守在集群节点上直接管理节点的 kubelet。
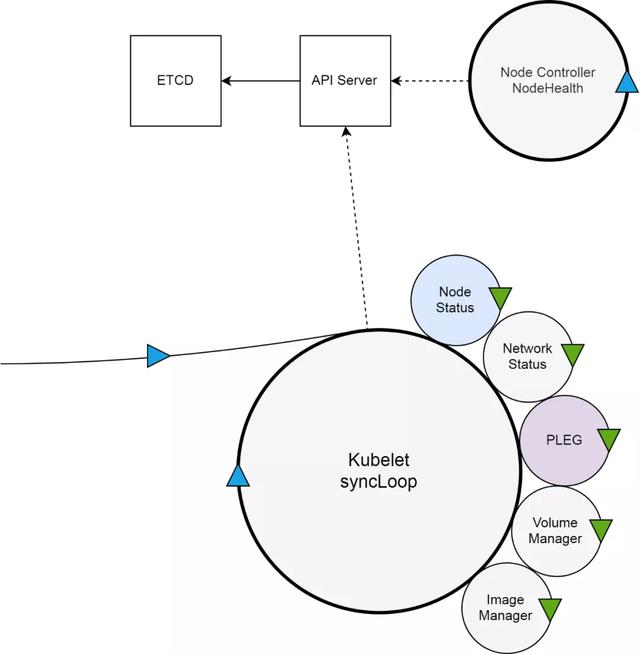
一方面,kubelet 扮演的是集群控制器的角色,它定期从 API Server 获取 Pod 等相关资源的信息,并依照这些信息,控制运行在节点上 Pod 的执行;另外一方面,kubelet 作为节点状况的监视器,它获取节点信息,并以集群客户端的角色,把这些状况同步到 API Server。
在这个问题中,kubelet 扮演的是第二种角色。
Kubelet 会使用上图中的 NodeStatus 机制,定期检查集群节点状况,并把节点状况同步到 API Server。而 NodeStatus 判断节点就绪状况的一个主要依据,就是 PLEG。
PLEG是Pod Lifecycle Events Generator的缩写,基本上它的执行逻辑,是定期检查节点上Pod运行情况,如果发现感兴趣的变化,PLEG 就会把这种变化包装成 Event 发送给 Kubelet 的主同步机制 syncLoop 去处理。但是,在 PLEG 的 Pod 检查机制不能定期执行的时候,NodeStatus 机制就会认为,这个节点的状况是不对的,从而把这种状况同步到 API Server。
而最终把 kubelet 上报的节点状况,落实到节点状态的是节点控制这个组件。这里我故意区分了 kubelet 上报的节点状况,和节点的最终状态。因为前者,其实是我们 describe node 时看到的 Condition,而后者是真正节点列表里的 NotReady 状态。

就绪三分钟
在问题发生之后,我们重启 kubelet,节点三分钟之后才会变成 NotReady 状态。这个现象是问题的一个关键切入点。
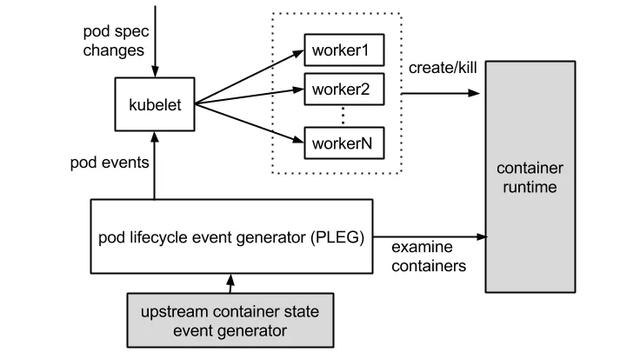
在解释它之前,请大家看一下官方这张 PLEG 示意图。这个图片主要展示了两个过程。
- 一方面,kubelet 作为集群控制器,从 API Server 处获取 pod spec changes,然后通过创建 worker 线程来创建或结束掉 pod;
- 另外一方面,PLEG 定期检查容器状态,然后把状态,以事件的形式反馈给 kubelet。
在这里,PLEG 有两个关键的时间参数:一个是检查的执行间隔,另外一个是检查的超时时间。以默认情况为准,PLEG 检查会间隔一秒,换句话说,每一次检查过程执行之后,PLEG 会等待一秒钟,然后进行下一次检查;而每一次检查的超时时间是三分钟,如果一次 PLEG 检查操作不能在三分钟内完成,那么这个状况,会被上一节提到的 NodeStatus 机制,当做集群节点 NotReady 的凭据,同步给 API Server。
而我们之所以观察到节点会在重启 kubelet 之后就绪三分钟,是因为 kubelet 重启之后,第一次 PLEG 检查操作就没有顺利结束。节点就绪状态,直到三分钟超时之后,才被同步到集群。
如下图,上边一行表示正常情况下 PLEG 的执行流程,下边一行则表示有问题的情况。relist 是检查的主函数。

温馨提示:
篇幅过长,建议扫描下方二维码获取全部内容
扫描下方二维码通过后回复
关键词:阿里云 !
文章来源于网络,侵删!