

这应该是最全的K8s-Pod调度策略了
API Server接受客户端提交Pod对象创建请求后的操作过程中,有一个重要的步骤就是由调度器程序kube-scheduler从当前集群中选择一个可用的最佳节点来接收并运行它,通常是默认的调度器kube-scheduler负责执行此类任务。
对于每个待创建的Pod对象来说,调度过程通常分为两个阶段—》过滤—》打分,过滤阶段用来过滤掉不符合调度规则的Node,打分阶段建立在过滤阶段之上,为每个符合调度的Node进行打分,分值越高则被调度到该Node的机率越大。
Pod调度策略除了系统默认的kube-scheduler调度器外还有以下几种实现方式:
1.nodeName(直接指定Node主机名)
2.nodeSelector (节点选择器,为Node打上标签,然后Pod中通过nodeSelector选择打上标签的Node)
3.污点taint与容忍度tolerations
4.NodeAffinity 节点亲和性
5.PodAffinity Pod亲和性
6.PodAntAffinity Pod反亲和性
以下几章节内容主要讲解上面几种调度策略以及kube-scheduler调度器的调度原理。
Pod调度之kube-scheduler
官方文档:
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/kube-scheduler/
kube-scheduler调度介绍
kube-scheduler是Kubernetes 集群的默认调度器,并且是集群控制面(master)的一部分。对每一个新创建的Pod或者是未被调度的Pod,kube-scheduler会选择一个最优的Node去运行这个Pod。
然而,Pod内的每一个容器对资源都有不同的需求,而且Pod本身也有不同的资源需求。因此,Pod在被调度到Node上之前,根据这些特定的资源调度需求,需要对集群中的Node进行一次过滤。
在一个集群中,满足一个Pod调度请求的所有Node称之为可调度节点。如果没有任何一个Node能满足Pod的资源请求,那么这个Pod将一直停留在未调度状态直到调度器能够找到合适的Node。
调度器先在集群中找到一个Pod的所有可调度节点,然后根据一系列函数对这些可调度节点打分,然后选出其中得分最高的Node来运行Pod。之后,调度器将这个调度决定通知给kube-apiserver,这个过程叫做绑定。
在做调度决定是需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等。
kube-scheduler 调度流程
kube-scheduler 给一个 pod 做调度选择包含两个步骤:
1.过滤(Predicates 预选策略)2.打分(Priorities 优选策略)
过滤阶段:过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下,这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
打分阶段:在过滤阶段后调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
整体流程如下图所示:
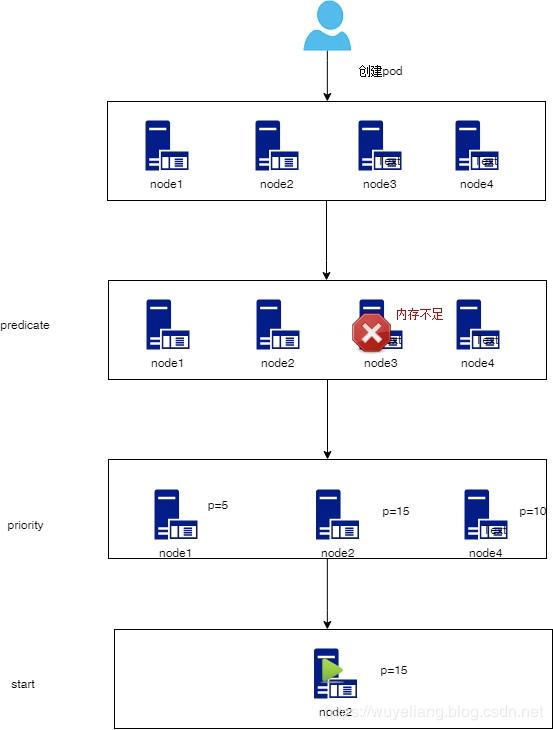

过滤阶段
官方文档:
https://kubernetes.io/docs/reference/scheduling/policies/
在调度时的过滤阶段到底时通过什么规则来对Node进行过滤的呢?就是通过以下规则!
1.PodFitsHostPorts:检查Node上是否不存在当前被调度Pod的端口(如果被调度Pod用的端口已被占用,则此Node被Pass)。
2.PodFitsHost:检查Pod是否通过主机名指定了特性的Node (是否在Pod中定义了nodeName)
3.PodFitsResources:检查Node是否有空闲资源(如CPU和内存)以满足Pod的需求。
4.PodMatchNodeSelector:检查Pod是否通过节点选择器选择了特定的Node (是否在Pod中定义了nodeSelector)。
5.NoVolumeZoneConflict:检查Pod请求的卷在Node上是否可用 (不可用的Node被Pass)。
6.NoDiskConflict:根据Pod请求的卷和已挂载的卷,检查Pod是否合适于某个Node (例如Pod要挂载/data到容器中,Node上/data/已经被其它Pod挂载,那么此Pod则不适合此Node)
7.MaxCSIVolumeCount::决定应该附加多少CSI卷,以及是否超过了配置的限制。
8.CheckNodeMemoryPressure:对于内存有压力的Node,则不会被调度Pod。
9.CheckNodePIDPressure:对于进程ID不足的Node,则不会调度Pod
10.CheckNodeDiskPressure:对于磁盘存储已满或者接近满的Node,则不会调度Pod。
11.CheckNodeCondition:Node报告给API Server说自己文件系统不足,网络有写问题或者kubelet还没有准备好运行Pods等问题,则不会调度Pod。
12.PodToleratesNodeTaints:检查Pod的容忍度是否能承受被打上污点的Node。
13.CheckVolumeBinding:根据一个Pod并发流量来评估它是否合适(这适用于结合型和非结合型PVCs)。
打分阶段
官方文档:
https://kubernetes.io/docs/reference/scheduling/policies/ 当过滤阶段执行后满足过滤条件的Node,将进行打分阶段。
1.SelectorSpreadPriority:优先减少节点上属于同一个 Service 或 Replication Controller 的 Pod 数量
2.InterPodAffinityPriority:优先将 Pod 调度到相同的拓扑上(如同一个节点、Rack、Zone 等)
3.LeastRequestedPriority:节点上放置的Pod越多,这些Pod使用的资源越多,这个Node给出的打分就越低,所以优先调度到Pod少及资源使用少的节点上。
4.MostRequestedPriority:尽量调度到已经使用过的 Node 上,将把计划的Pods放到运行整个工作负载所需的最小节点数量上。
5.RequestedToCapacityRatioPriority:使用默认资源评分函数形状创建基于requestedToCapacity的
ResourceAllocationPriority。
6.BalancedResourceAllocation:优先平衡各节点的资源使用。
7.NodePreferAvoidPodsPriority:根据节点注释对节点进行优先级排序,以使用它来提示两个不同的 Pod 不应在同一节点上运行。
scheduler.alpha.kubernetes.io/preferAvoidPods。
8.NodeAffinityPriority:优先调度到匹配 NodeAffinity (Node亲和性调度)的节点上。
9.TaintTolerationPriority:优先调度到匹配 TaintToleration (污点) 的节点上
10.ImageLocalityPriority:尽量将使用大镜像的容器调度到已经下拉了该镜像的节点上。
11.ServiceSpreadingPriority:尽量将同一个 service 的 Pod 分布到不同节点上,服务对单个节点故障更具弹性。
12.EqualPriority:将所有节点的权重设置为 1。
13.EvenPodsSpreadPriority:实现首选pod拓扑扩展约束。
kube-scheduler 调度示例
默认配置使用的就是kube-scheduler调度组件,我们下面例子启动三个Pod,看分别被分配到哪个Node。
1.创建资源配置清单
cat scheduler-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: scheduler-deploy
spec:
replicas: 3
selector:
matchLabels:
app: scheduler-pod
template:
metadata:
labels:
app: scheduler-pod
spec:
containers:
- image: busybox:latest
name: scheduler-pod
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]2.使用kubectl创建资源对象
kubectl apply -f scheduler-pod.yaml3.查看被kube-scheduler自动调度的Pod 两个Pod在Node03上,一个在Node02上
kubectl get pods -o wide | grep scheduler
scheduler-deploy-65d8f9c98-cqdm9 1/1 Running 0 111s 10.244.5.59 k8s-node03 <none> <none>
scheduler-deploy-65d8f9c98-d4t9p 1/1 Running 0 111s 10.244.5.58 k8s-node03 <none> <none>
scheduler-deploy-65d8f9c98-f8xxc 1/1 Running 0 111s 10.244.2.45 k8s-node02 <none> <none>4.我们查看一下Node资源的使用情况 Node01,可用内存2.7G

Node02,可用内存5.8G

Node03,可用内存5.6G

所以默认的kube-scheduler调度策略经过了过滤和打分后,将以上三个Pod分布在Node2和Node3上。
Pod调度之nodeName
nodeNamed这种调度方式比较简单,我们可以指定Pod在哪台Node上进行运行,通过spec.nodeName参数来指定Node主机名称即可。
1、创建资源配置清单
cat nodeName-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodename-pod
spec:
#指定该Pod运行在k8s-node02节点上
nodeName: k8s-node02
containers:
- image: busybox:latest
name: nodename-containers
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]2、创建Pod资源对象
kubectl apply -f nodeName-pod.yaml3、查看Pod调度节点
如下,nodename-pod被绑定在了k8s-node02上
kubectl get pods -o wide | grep name
nodename-pod 1/1 Running 0 25s 10.244.2.46 k8s-node02 <none> <none>Pod调度之nodeSelector
nodeSelector用于将Pod调度到匹配Label的Node上,所以要先给node打上标签,然后在Pod配置清单中选择指定Node的标签。先给规划node用途,然后打标签,例如将两台node划分给不同团队使用:
为Node添加标签
k8s-node02给开发团队用,k8s-node03给大数据团队用
1.添加标签
kubectl get nodes -o wide --show-labels2.查看标签
kubectl apply -f nodeSelector-pod.yaml创建资源配置清单
cat nodeSelector-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nodeselector-pod
spec:
nodeSelector: #指定标签选择器
team: development #label指定开发团队的label
containers:
- image: busybox:latest
name: nodeselector-containers
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]创建Pod对象
kubectl apply -f nodeSelector-pod.yaml查看pod被分配的Node
kubectl get pods -o wide | grep nodeselect
nodeselector-pod 1/1 Running 0 49s 10.244.2.47 k8s-node02 <none> <none>删除标签
kubectl label nodes k8s-node02 team-
kubectl label nodes k8s-node03 team-删除标签后pod还在正常运行
kubectl get pods -o wide | grep nodeselect
nodeselector-pod 1/1 Running 0 11m 10.244.2.47 k8s-node02 <none> <none>把Pod删除然后再次创建Pod
kubectl get pods -o wide | grep nodeselectnodeselector-pod 0/1 Pending 0 55s <none> <none> <none> <none>会发现该pod一直在等待中,找不到清单中配置标签的Node
kubectl describe pods/nodeselector-pod | grep -A 10 EventsEvents: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/6 nodes are available: 6 node(s) didn't match node selector. Warning FailedScheduling <unknown> default-scheduler 0/6 nodes are available: 6 node(s) didn't match node selector.事件:6个节点都不匹配 node selector
kubectl describe pods/nodeselector-pod | grep -A 10 Events
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/6 nodes are available: 6 node(s) didn't match node selector.
Warning FailedScheduling <unknown> default-scheduler 0/6 nodes are available: 6 node(s) didn't match node selector.Pod调度之污点与容忍
官方文档:
https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/#example-use-cases
污点(taint)是定义在Node之上的键值型的数据,用于让节点拒绝将Pod调度运行于其上,除非该Pod对象具有接纳Node污点的容忍度。而容忍度(tolerations)是定义在Pod对象的键值型属性数据,用于·配置其可容忍的Node污点,而且调度器仅能将Pod对象调度至其能够容忍该Node污点的Node之上。
如下图所示:
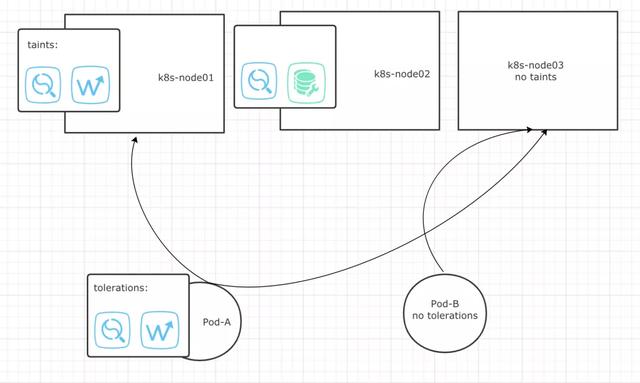
•Pod-A具备k8s-node01污点的容忍度,所以能够被调度器调度至k8s-node01上。•Pod-A不完全具备k8s-node02污点的容忍度,所以不能被调度至k8s-node02。•Pod-A虽然具备容忍度,但同样可以调度至没有污点的k8s-node03节点上。•Pod-B自身没有容忍度,所以只能被调度至没有污点的k8s-node03节点上。
污点介绍及定义
1.污点类型介绍 污点定义在nodeSpec中,容忍度定义在PodSpec中,他们都是键值型数据,但又都额外支持一个效果(effect)标记,语法格式为 “key=value:effect” ,其中key和value的用法及格式与资源注解信息相似,而effect则用于定义对Pod对象的排斥等级,它主要包含以下三种排斥类型。
•NoSchedule :为Node添加污点等级为NoSchedule,除容忍此污点的Pod以外的其它Pod将不再被调度到本机。
•PreferNoSchedule:为Node添加污点等级为PreferNoSchedule,不能容忍此污点的Pod对象尽量不要调度到当前节点,如果没有其它节点可以供Pod选择时,也会接受没有容忍此污点的Pod对象。
•NoExecute:为Node添加污点等级为NoExecute,能容忍此污点的Pod将被调度到此节点,而且节点上现存的Pod对象因节点使用了NoExceute等级的污点,则现存的Pod将被驱赶至其它满足条件的Node(除非现存Pod容忍了当前节点的污点)。
2.Master污点介绍 以kubeadm部署的kubernetes集群,其Master节点将自动添加污点信息以阻止不能容忍此污点的Pod对象调度至此节点,因此用户可以手动创建Pod来容忍Master的污点。
查看kubernetes集群中master节点的污点:
kubectl get pods -o wide | grep nodeselectnodeselector-pod 1/1 Running 0 49s 10.244.2.47 k8s-node02 <none> <none>不过,有些系统级别应用,如kube-proxy或者kube-flannel等也是以Pod形式运行在集群上,这些资源在创建时就添加上了相应的容忍度以确保他们被 DaemonSet 控制器创建时能够调度至 Master 节点运行一个实例。
查看系统级别Pod的容忍度
kubectl describe pods/etcd-k8s-master01 pods/etcd-k8s-master01 pods/kube-flannel-ds-amd64-2smzp pods/kube-flannel-ds-amd64-2smzp -n kube-system | grep Tolerations
Tolerations: :NoExecute
Tolerations: :NoExecute
Tolerations: :NoSchedule
Tolerations: :NoSchedule另外,这类Pod是构成Kubernetes系统的基础且关键的组件,它们甚至还定义了更大的容忍度,从下面某kube-flannel实例的容忍度定义来看,它还能容忍那些报告了磁盘压力或内存压力的节点,以及未就绪的节点和不可达的节点,以确保它们能在任何状态下正常调度至集群节点上运行。
kubectl describe pods kube-flannel-ds-amd64-2smzp -n kube-system
Tolerations: :NoSchedule
node.kubernetes.io/disk-pressure:NoSchedule
node.kubernetes.io/memory-pressure:NoSchedule
node.kubernetes.io/network-unavailable:NoSchedule
node.kubernetes.io/not-ready:NoExecute
node.kubernetes.io/pid-pressure:NoSchedule
node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unschedulable:NoSchedule
Events: <none>3.定义污点
定义污点语法 kubectl taint nodes <node-name> <key>=<value>:<effect>
node-name:指定需要打污点的Node主机名 key=value:指定污点的键值型数据 effect:为污点的等级
key名称长度上线为253个字符,可以使用字母或者数字开头,支持字母、数字、连接符、点号、下划线作为key或者value。value最长是 63个字符。污点通常用于描述具体的部署规划,它们的键名形式如 node-type、node-role、node-project、node-geo等。
1.添加污点 为k8s-node02添加污点,污点程度为NoSchedule,type=calculate为标签
kubectl taint node k8s-node02 type=calculate:NoSchedule2.查看污点
kubectl describe nodes k8s-node02 | grep Taints这样的话我们创建Pod就不会被调度到我们打上污点的k8s-node02的节点上
3.创建Pod资源配置清单 我们创建3个Pod,看看其是否会将Pod调度到我们打污点Node上
cat taint-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint-deploy
spec:
replicas: 3
selector:
matchLabels:
app: taint-pod
template:
metadata:
labels:
app: taint-pod
spec:
containers:
- image: busybox:latest
name: taint-pod
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]2.查看Pod被调度的Node 下面三个Pod都被调度到了Node03上,效果可能不是很明显,我们为Node02打了污点,还有Node01没有体现出来
kubectl apply -f taint-pod.yaml
kubectl get pods -o wide | grep taint
taint-deploy-748989f6d4-f7rbq 1/1 Running 0 41s 10.244.5.62 k8s-node03 <none> <none>
taint-deploy-748989f6d4-nzwjg 1/1 Running 0 41s 10.244.5.61 k8s-node03 <none> <none>
taint-deploy-748989f6d4-vzzdx 1/1 Running 0 41s 10.244.5.60 k8s-node03 <none> <none>4.扩容Pod 我们将Pod扩容至9台,让Pod分配到Node01节点,可以直观的展现污点
kubectl scale --replicas=9 deploy/taint-deploy -n default
kubectl get pods -o wide | grep taint
taint-deploy-748989f6d4-4ls9d 1/1 Running 0 54s 10.244.5.65 k8s-node03 <none> <none>
taint-deploy-748989f6d4-794lh 1/1 Running 0 68s 10.244.5.63 k8s-node03 <none> <none>
taint-deploy-748989f6d4-bwh5p 1/1 Running 0 54s 10.244.5.66 k8s-node03 <none> <none>
taint-deploy-748989f6d4-ctknr 1/1 Running 0 68s 10.244.5.64 k8s-node03 <none> <none>
taint-deploy-748989f6d4-f7rbq 1/1 Running 0 2m27s 10.244.5.62 k8s-node03 <none> <none>
taint-deploy-748989f6d4-hf9sf 1/1 Running 0 68s 10.244.3.51 k8s-node01 <none> <none>
taint-deploy-748989f6d4-nzwjg 1/1 Running 0 2m27s 10.244.5.61 k8s-node03 <none> <none>
taint-deploy-748989f6d4-prg2f 1/1 Running 0 54s 10.244.3.52 k8s-node01 <none> <none>
taint-deploy-748989f6d4-vzzdx 1/1 Running 0 2m27s 10.244.5.60 k8s-node03 <none> <none>以上调度了两台Pod到Node02,目前Node03和Node01都可以分配到Pod,而被打了污点的Node02无法分配Pod
5.删除污点 删除污点之需要指定标签的 key 及污点程度
kubectl taint node k8s-node02 type:NoSchedule-容忍度介绍及定义
Pod对象的容忍度可以通过其spec.tolerations字段进行添加,根据使用的操作符不同,主要有两种可用的形式:
1.容忍度与污点信息完全匹配的等值关系,使用Equal操作符。2.判断污点是否存在的匹配方式,使用Exists操作富。
容忍度所用到的参数tolerations,tolerations参数下的还有以下几个二级参数:
•operator:此值被称为运算符,值可以为[Equal|Exists],Equal表示污点的key是否等于value(默认参数),Exists只判断污点的key是否存在,使用该参数时,不需要定义value。
•effect:指定匹配的污点程度,为空表示匹配所有等级的污点,值可以为 [NoSchedule|PreferNoSchedule|NoExecut]。
•key:指定Node上污点的键key。
•value:指定Node上污点的值value。
•tolerationSeconds:用于定于延迟驱赶当前Pod对象的时长,如果设置为0或者负值系统将立即驱赶当前Pod。(单位为秒)
1. 为Node打上不同的等级污点
kubectl taint nodes k8s-node01 nodes=gpu:NoSchedule
kubectl taint nodes k8s-node02 data=ssd:PreferNoSchedule
kubectl taint nodes k8s-node03 traffic=proxy:NoExecute2.查看三个Node被打上的污点
kubectl describe nodes k8s-node01 k8s-node02 k8s-node03 | grep Taint
Taints: nodes=gpu:NoSchedule
Taints: data=ssd:PreferNoSchedule
Taints: traffic=proxy:NoExecute3.创建容忍NoSchedule级别污点的Pod并查看Pod调度结果
cat pod-tolerations.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-noschedule
spec:
containers:
- name: gpu-container
image: busybox:latest
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]
tolerations:
- key: "nodes" #指定污点的key
operator: "Equal" #Equal值表示我们指定的key必须要等于value
value: "gpu" #指定value
effect: "NoSchedule" #指定污点级别
#调度结果如我们期望所致在node01上
kubectl get pods -o wide | grep pod-noschedule
pod-noschedule 1/1 Running 0 58s 10.244.3.62 k8s-node01 <none> <none>4.创建容忍PreferNoSchedule级别污点的Pod并查看Pod调度结果
cat pod-tolerations.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-prefernoschedule
spec:
containers:
- name: ssd-container
image: busybox:latest
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]
tolerations:
- key: "data"
operator: "Exists" #Exists参数,只判断key等于data是否存在,不需要关心value是什么
effect: "PreferNoSchedule
#调度结果如我们期望所致在node02上
kubectl get pods -o wide | grep pod-prefer
pod-prefernoschedule 1/1 Running 0 45s 10.244.2.82 k8s-node02 <none> <none>5.创建容忍NoExecute级别污点的Pod并查看调度结果
apiVersion: v1
kind: Pod
metadata:
name: pod-noexecute
spec:
containers:
- name: proxy-container
image: busybox:latest
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]
tolerations:
- key: "traffic"
operator: "Equal"
value: "proxy"
effect: "NoExecute" #指定污点级别
tolerationSeconds: 300 #指定驱赶当前Node上Pod的延迟时间
#调度结果在Node03上
kubectl get pods -o wide | grep pod-noexecute
pod-noexecute 1/1 Running 0 24s 10.244.5.89 k8s-node03 <none> <none>6.创建没有容忍度的Pod并查看调度结果 PreferNoSchedule污点级别为尽量不接受没有容忍此污点的Pod,如果没有其它节点可以供Pod选择时,也会接受没有容忍此污点的Pod对象。所以创建一个没有容忍度的Pod看其调度结果。
cat pod-tolerations.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-notolerations
spec:
containers:
- name: notolerations-container
image: busybox:latest
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]
#如下,调度结果与我们料想一致
kubectl get pods -o wide | grep pod-notolerations
pod-notolerations 1/1 Running 0 29s 10.244.2.83 k8s-node02 <none> <none>实践中,若集群中的一组机器专用于为运行非生产典型的容器应用而备置,而且它们可能随时按需上下线,那么就应该为其添加污点信息,以确保仅那些能够容忍此污点的非生产型Pod对象可以调度到其上,另外,某些有种特殊硬件的节点需要专用于运行一类有着SSD、或者GPU的设备,也应该为其添加污点信息以排除其它Pod对象。
Pod调度之节点亲和性调度
官方文档:
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
节点亲和性调度程序是用来确定Pod对象调度位置的一组规则,这些规则基于节点上的自定义标签和Pod对象上指定的标签选择器进行定义。
节点亲和性允许Pod对象定义针对一组可以调度于其上的节点的亲和性或反亲和性,不过,它无法具体到某个特定的节点。例如将Pod调度至有着CPU的节点或者一个可用区域内的节点之上。定义节点亲和性规则时有两种类型的节点亲和性规则:
1.硬亲和性(required):硬亲和性实现的是强制性规则,它是Pod调度时必须要满足的规则,而在不存在满足规则的Node时,Pod对象会被置为Pending状态。
2.软亲和性(preferred):软亲和性规则实现的是一种柔性调度限制,它倾向于将Pod对象运行于某类特定节点之上,而调度器也将尽量满足此需求,但在无法满足需求时它将退而求其次地选择一个不匹配规则的节点之上。
定义节点亲和性规则的关键点有两个:
1.为节点配置合乎需求的标签。
2.为Pod对象定义合理的标签选择器,从而能够基于标签选择器选择出符合需求的标签。
不过,如
requiredDuringSchedulingIgnoredDuringExecution和
preferredDuringSchedulingIgnoredDuringExecution名字中的后半段字符串IgnoredDuringExecution隐藏的意义所指,在Pod资源基于节点亲和性规则调度至某节点之后,节点标签发生了改变而不在符合此类节点亲和性规则时,调度器不会将Pod对象从此节点移除,因为它仅对新建的Pod对象生效。
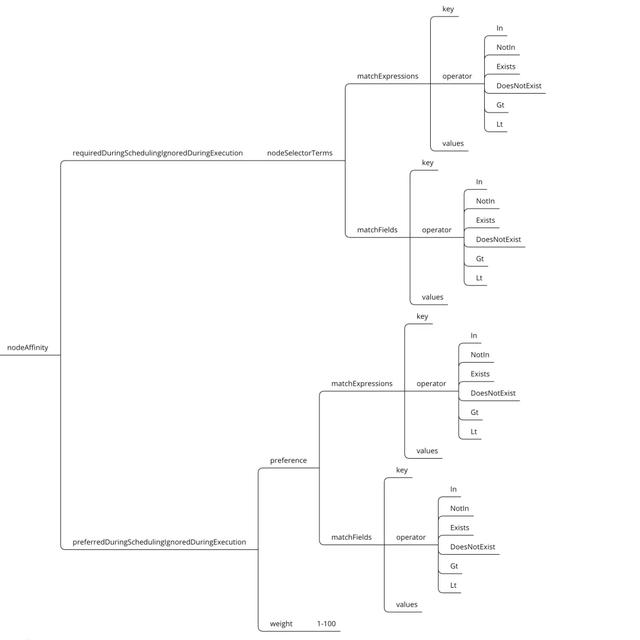
帮助文档:kubectl explain
pods.spec.affinity.nodeAffinity
节点硬亲和性
节点硬亲和性类似于Pod对象使用nodeSelector属性可以基于节点标签匹配的方式将Pod对象调度至某一个节点之上。不过它仅能基于简单的等值关系定义标签选择器,而nodeAffinity中支持使用matchExpressions属性构建更为复杂的标签选择机制。
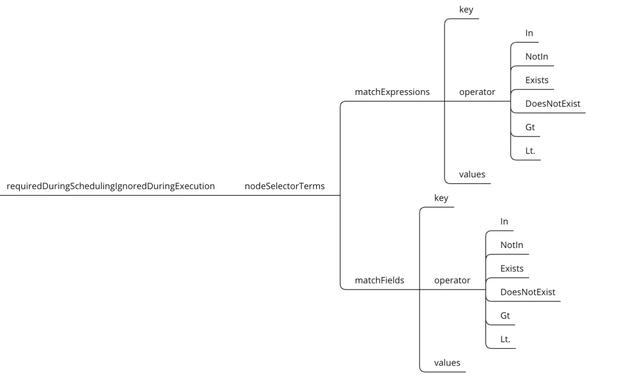
节点硬亲和性参数解析:
•nodeSelectorTerms:节点选择列表(比nodeSelector高级一点)。
•matchExpressions:按照节点label列出节点选择器列表。(与matchFields是两种方式,不过结果是一至)
•matchFields:按照节点字段列出节点选择器列表。(与matchExpressions是两种方式,不过结果是一至)
•key:指定要选择节点label的key。
•values:指定要选择节点label的value,值必须为数组 ["value"] ,如果操作符为In或者 Notin,value则不能为空,如果操作符为Exists或者DoesNotExist ,value则必须为空[],如果操作符为Gt或Lt,则value必须有单个元素,该元素将被解释为整数。
•operator:操作符,指定key与value的关系。
•In:key与value同时存在,一个key多个value的情况下,value之间就成了逻辑或效果。
•NotIn:label 的值不在某个列表中。
•Exists:只判断是否存在key,不用关心value值是什么。
•DoesNotExist:某个 label 不存在。
•Gt:label 的值大于某个值。
•Lt:label 的值小于某个值
1.为Node打上标签
#node01打两个标签ssd=true及zone=foo
kubectl label node k8s-node01 ssd=true zone=foo
#node02打一个标签zone=foo
kubectl label node k8s-node02 zone=foo
#node03打两个标签ssd=true zone=bar
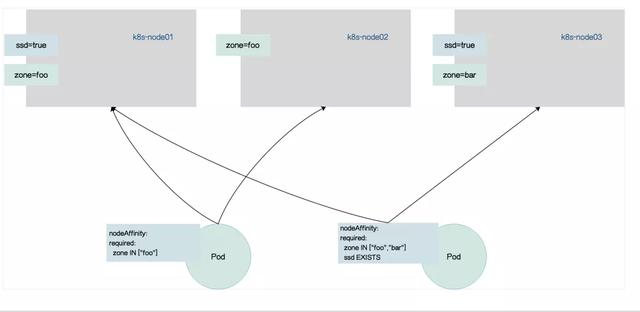
kubectl label node k8s-node03 ssd=true zone=bar2.创建Pod资源配置清单 下面Pod资源清单中,该Pod将被绑定到标签key为zone,value为foo的Node上,符合该规则有两个Node,分别是Node01和Node02,下面资源配置清单中只创建了一个Pod,可以来观察下该Pod会被调度至Node01还是Node02。
apiVersion: apps/v1
kind: Deployment
metadata:
name: required-nodeaffinity-deploy
labels:
type: required-deploy
spec:
replicas: 3
selector:
matchLabels:
app: required-nodeaffinity-pod
template:
metadata:
labels:
app: required-nodeaffinity-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- { key: zone, operator: In, values: ["foo"] }
containers:
- name: myapp
image: busybox:latest
command: ["/bin/sh", "-c", "tail -f /etc/passwd"]3.查看Pod被调度至哪台Node 如下结果可以看到三个Pod都被调度到了Node01上
kubectl apply -f required-nodeAffinity-pod.yaml
kubectl get pods -o wide | grep requ
required-nodeaffinity-deploy-55448998fd-hm9ww 0/1 ContainerCreating 0 7s <none> k8s-node01 <none> <none>
required-nodeaffinity-deploy-55448998fd-pkwph 0/1 ContainerCreating 0 7s <none> k8s-node01 <none> <none>
required-nodeaffinity-deploy-55448998fd-z94v2 0/1 ContainerCreating 0 7s <none> k8s-node01 <none> <none>4.创建Pod资源清单2 如下value有两个值,两个值之间是或关系,可以调度到key为zone,values为foo或者bar标签的Node上, 下面配置清单中有两个key,两个key之间是与关系,第二个key在第一个key的基础上,Node还有有标签key为ssd,values无需关心,因为使用操作符Exists。下面的配置清单中,只能调度到标签key为zone,values为foo或者bar以及key为ssd的Node上,满足此需求的Node有Node01和Node03。
cat required-nodeAffinity-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: required-nodeaffinity-deploy
labels:
type: required-deploy
spec:
replicas: 3
selector:
matchLabels:
app: required-nodeaffinity-pod
template:
metadata:
labels:
app: required-nodeaffinity-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- { key: zone, operator: In, values: ["foo","bar"] } #foo和bar之间是或关系
- { key: ssd, operator: Exists, values: [] } #两个matchExpressions之间是与关系
containers:
- name: myapp
image: busybox:latest
command: ["/bin/sh", "-c", "tail -f /etc/passwd"]5.查看Pod调度结果 如下三个Pod都被调度在Node03节点
kubectl apply -f required-nodeAffinity-pod.yaml
kubectl get pods -o wide | grep required-nodeaffinity
required-nodeaffinity-deploy-566678b9d8-c84nd 1/1 Running 0 65s 10.244.5.97 k8s-node03 <none> <none>
required-nodeaffinity-deploy-566678b9d8-pn27p 1/1 Running 0 65s 10.244.5.95 k8s-node03 <none> <none>
required-nodeaffinity-deploy-566678b9d8-x8ttf 1/1 Running 0 65s 10.244.5.96 k8s-node03 <none> <none>节点软亲和性
节点软亲和性为节点选择机制提供了一种柔性控逻辑,当调度的Pod对象不再是"必须",而是“应该”放置于某些特性节点之上,当条件不满足时,它也能够接受编排于其它不符合条件的节点之上,另外,它还为每种倾向性提供了weight属性以便用户定义其优先级,取值范围是1-100,数字越大优先级越高。
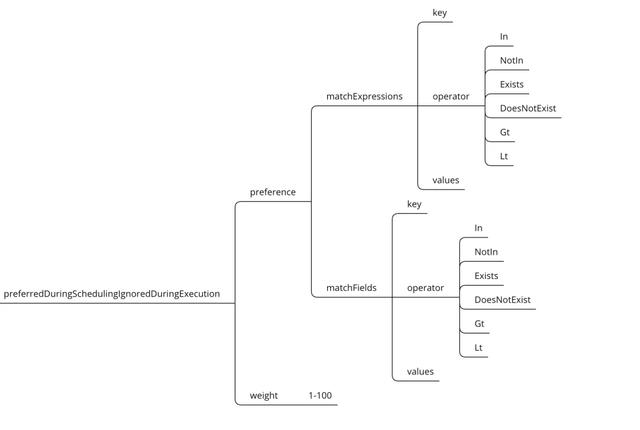
节点软亲和性参数解析:
•preference:节点选择器,与相应的权重相关联。
•weight:在1-100范围内,与匹配相应的节点选项相关联的权重。
•matchExpressions:按照节点label列出节点选择器列表。(与matchFields是两种方式,不过结果是一至)
•matchFields:按照节点字段列出节点选择器列表。(与matchExpressions是两种方式,不过结果是一至)
•key:指定要选择节点label的key。
•values:指定要选择节点label的value,值必须为数组 ["value"] ,如果操作符为In或者 Notin,value则不能为空,如果操作符为Exists或者DoesNotExist ,value则必须为空[""],如果操作符为Gt或Lt,则value必须有单个元素,该元素将被解释为整数。
•operator:操作符,指定key与value的关系。
•In:key与value同时存在,一个key多个value的情况下,value之间就成了逻辑或效果。
•NotIn:label 的值不在某个列表中。
•Exists:只判断是否存在key,不用关心value值是什么。
•DoesNotExist:某个 label 不存在。
•Gt:label 的值大于某个值。
•Lt:label 的值小于某个值
1.创建Pod资源配置清单 如下示例中,Pod模版定义了Node软亲和性运行在标签key为zone和values为foo或bar上,以及key为ssd(值无需担心是什么)的Node之上,符合以下需求的是Node01和Node03,但是如下第一个条件key为zoo的权重为60,而key为ssd的为30,所以第一个条件的权重要比第二个条件的权重高一倍,我们下面运行了3个Pod,调度器应该会在Node01上分配两个Pod,Node03上分配1个Pod。
cat preferred-nodeAffinitt-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: preferred-nodeaffinity-deploy
labels:
type: preferred-deploy
spec:
replicas: 3
selector:
matchLabels:
app: preferred-nodeaffinity-pod
template:
metadata:
labels:
app: preferred-nodeaffinity-pod
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 60
preference:
matchExpressions:
- { key: zone, operator: In, values: ["foo","bar"] }
- weight: 30
preference:
matchExpressions:
- { key: ssd, operator: Exists, values: [] }
containers:
- name: myapp
image: busybox:latest
command: ["/bin/sh", "-c", "tail -f /etc/passwd"]2.查看调度结果
kubectl get pods -o wide | grep preferred
preferred-nodeaffinity-deploy-5bf4699fd9-pcxvz 1/1 Running 0 5m32s 10.244.5.98 k8s-node03 <none> <none>
preferred-nodeaffinity-deploy-5bf4699fd9-phm8b 1/1 Running 0 5m32s 10.244.3.106 k8s-node01 <none> <none>
preferred-nodeaffinity-deploy-5bf4699fd9-xf87j 1/1 Running 0 5m32s 10.244.3.105 k8s-node01 <none> <none>3.创建标签key为app,值为proxy或者web的Pod
cat app_proxy.yaml
apiVersion: v1
kind: Pod
metadata:
name: app-proxy-pod
labels:
app: proxy
spec:
containers:
- name: app-proxy
image: busybox:latest
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]4.查看调度结果
kubectl apply -f app_proxy.yaml
#具备标签key为app,values的Pod被调度到了node03上
kubectl get pods -owide | grep app-proxy
app-proxy-pod 1/1 Running 0 42s 10.244.5.102 k8s-node03 <none> <none>
#如下podAffinity硬亲和性调度也被调度到此Node
kubectl get pods -owide | grep podaff
podaffinity-required-pod 1/1 Running 0 2m30s 10.244.5.103 k8s-node03 <none> <none>Pod调度之Pod亲和性调度
podAffinity介绍
出于高效通信的需求,我们要把几个Pod对象运行在比较近的位置,例如APP Pod与DB Pod,我们的APP Pod需要连接DB Pod,这个时候就需要把这两个Pod运行在较近的位置以便于网络通信,一般可以按照区域、机房、地区等来划分。像这种类型就属于Pod的亲和性调度。但是有时候出于安全或者分布式考虑,也有可能将Pod运行在不同区域、不同机房,这个时候Pod的关系就是为反亲和性。
podAffinity也被分为硬亲和性和软亲和性,其原理与Node中的硬亲和性及软亲和性一致。
硬亲和性(required):硬亲和性实现的是强制性规则,它是Pod调度时必须要满足的规则,而在不存在满足规则的Node时,Pod对象会被置为Pending状态。
软亲和性(preferred):软亲和性规则实现的是一种柔性调度限制,它倾向于将Pod对象运行于某类特定节点之上,而调度器也将尽量满足此需求,但在无法满足需求时它将退而求其次地选择一个不匹配规则的节点之上。
定义Pod亲和性规则的关键点有两个:
1.为节点配置合乎需求的标签。
2.为Pod对象定义合理的标签选择器labelSelector,从而能够基于标签选择器选择出符合需求的标签。
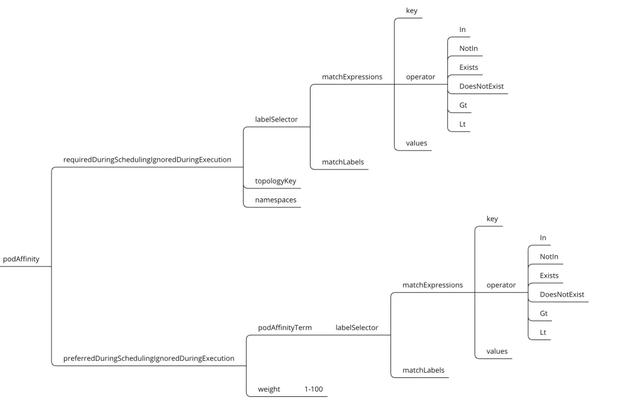
Pod反亲和硬亲和性
Pod硬亲和性调度使用
requiredDuringSchedulingIgnoredDuringExecution属性进行定义,Pod硬亲和性使用topologyKey参数来指定要运行在具备什么样标签key的Node上,然后再通过labelSelector选择你想关联Pod的标签,可能有点绕,下面看示例应该就明白了。
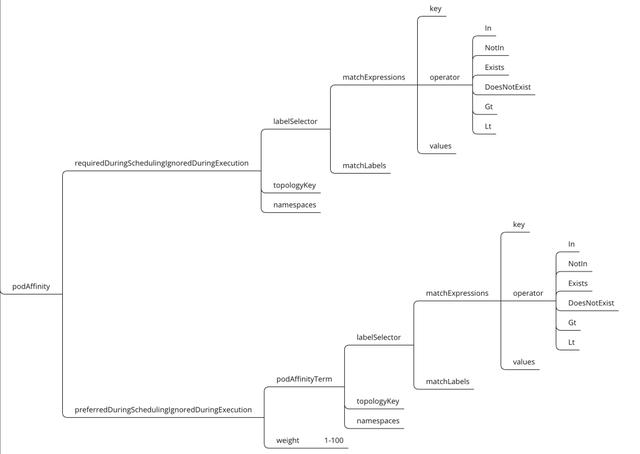
Pod硬亲和性参数解析:
•labelSelector:标签选择器️。
•topologyKey:指定要将当前创建Pod运行在具备什么样的Node标签上,通常指定Node标签的Key。
•namespaces:指定labelSelector应用于哪个名称空间,null或空列表表示“此pod的名称空间”。
•matchExpressions:按照Pod label列出节点选择器列表。(与matchLabels是两种方式,不过结果是一至)。
•matchLabels:按照节点字段列出节点选择器列表。(与matchExpressions是两种方式,不过结果是一至)。
•key:指定要选择节点label的key。
•values:指定要选择节点label的value,值必须为数组 ["value"] ,如果操作符为In或者 Notin,value则不能为空,如果操作符为Exists或者DoesNotExist ,value则必须为空[],如果操作符为Gt或Lt,则value必须有单个元素,该元素将被解释为整数。
•operator:操作符,指定key与value的关系。
•In:key与value同时存在,一个key多个value的情况下,value之间就成了逻辑或效果。
•NotIn:label 的值不在某个列表中。
•Exists:只判断是否存在key,不用关心value值是什么。
•DoesNotExist:某个 label 不存在。
•Gt:label 的值大于某个值。
•Lt:label 的值小于某个值
1.为Node打上不同地区的标签 node01标签为beijing node02标签为shanghai node03标签为shenzhen
kubectl label node k8s-node01 zone=beijing
kubectl label node k8s-node02 zone=shanghai
kubectl label node k8s-node03 zone=shenzhen2.创建资源配置清单 下面清单中,Pod首先会选择标签key为zone的Node,我们上面做了三个Node标签key都为zone,匹配之后,开始在标签key为zone的Node上寻找标签key为app,values为proxy或者web的Pod,然后与其运行在那台Node之上。
cat podaffinity-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: podaffinity-required-pod
spec:
containers:
- name: nginx-containers
image: nginx:latest
affinity:
podAffinity:
#硬亲和性
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
#选择标签key为app,values为proxy或者web的Pod,然后与其运行在同一个Node上
- { key: app, operator: In, values: ["proxy","web"] }
#选择key为zone的Node
topologyKey: zone3.查看调度结果 如下可以看到,三台Node上没有标签key为app,values为proxy或者web的Pod,我们采用的是硬亲和性,所以该Pod一直为Pending状态。
kubectl apply -f podaffinity-pod.yaml
kubectl get pods -o wide | grep podaffinity
podaffinity-required-pod 0/1 Pending 0 3m43s <none> <none> <none> <none>4.创建标签key为app,值为proxy或者web的Pod
cat app_proxy.yaml
apiVersion: v1
kind: Pod
metadata:
name: app-proxy-pod
labels:
app: proxy
spec:
containers:
- name: app-proxy
image: busybox:latest
command: [ "/bin/sh", "-c", "tail -f /etc/passwd" ]5.查看调度结果
kubectl apply -f app_proxy.yaml
#具备标签key为app,values的Pod被调度到了node03上
kubectl get pods -owide | grep app-proxy
app-proxy-pod 1/1 Running 0 42s 10.244.5.102 k8s-node03 <none> <none>
#如下podAffinity硬亲和性调度也被调度到此Node
kubectl get pods -owide | grep podaff
podaffinity-required-pod 1/1 Running 0 2m30s 10.244.5.103 k8s-node03 <none> <none>Pod软亲和性
Pod软亲和性使用
preferredDuringSchedulingIgnoredDuringExecution属性进行定义,Pod软亲和性使用podAffinityTerm属性来挑选Pod标签,当调度的Pod对象不再是”必须”,而是“应该”放置于某些特性节点之上,当条件不满足时,它也能够接受编排于其它不符合条件的节点之上,另外,它还为每种倾向性提供了weight属性以便用户定义其优先级,取值范围是1-100,数字越大优先级越高。
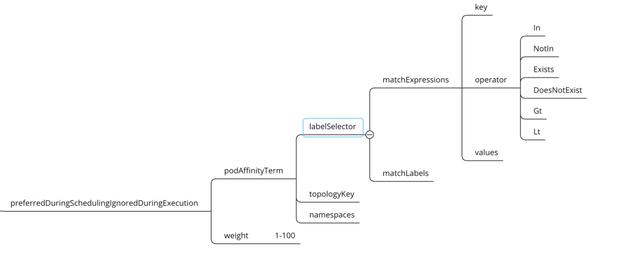
•Pod软亲和性参数解析:
•podAffinityTerm:Pod亲和性选择器。
•weight:在1-100范围内,与匹配相应的节点选项相关联的权重。
•labelSelector:标签选择器。
•matchExpressions:按照Pod label列出节点选择器列表。(与matchLabels是两种方式,不过结果是一至)。
•matchLabels:按照节点字段列出节点选择器列表。(与matchExpressions是两种方式,不过结果是一至)。
•key:指定要选择节点label的key。
•values:指定要选择节点label的value,值必须为数组 ["value"] ,如果操作符为In或者 Notin,value则不能为空,如果操作符为Exists或者DoesNotExist ,value则必须为空[],如果操作符为Gt或Lt,则value必须有单个元素,该元素将被解释为整数。
•operator:操作符,指定key与value的关系。
•In:key与value同时存在,一个key多个value的情况下,value之间就成了逻辑或效果
•NotIn:label 的值不在某个列表中。
•Exists:只判断是否存在key,不用关心value值是什么。
•DoesNotExist:某个 label 不存在。
•Gt:label 的值大于某个值。
•Lt:label 的值小于某个值
1.创建资源配置清单
下面创建一个Pod软亲和性资源配置清单,定义了两组亲和性判断机制,一个是选择cache Pod所在节点的zone标签,并赋予权重为80,另一个是选择db Pod所在的zone标签,权重为20,调度器首先会将Pod调度到具有zone标签key的Node上,然后将多数Pod调度到具备标签为app=cache的Pod同节点,其次调度到具备标签app=db的Pod同节点。
如果Node上的Pod都具备app=cache和app=db,那么根据Pod软亲和性策略,调度器将退而求其次的将Pod调度到其它Node,如果甚至连Node都具备标签zone键,那么根据软亲和策略,调度器还是会退而求其次的将Pod调度到不存在zone键的Node上。
cat podaffinity-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podaffinity-perferred-pod
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
podAffinityTerm:
labelSelector:
matchExpressions:
- { key: app, operator: In, values: ["cache"] }
topologyKey: zone
- weight: 20
podAffinityTerm:
labelSelector:
matchExpressions:
- { key: app, operator: In, values: ["db"] }
topologyKey: zone
containers:
- name: myapp
image: busybox:latest
command: ["/bin/sh", "-c", "tail -f /etc/passwd" ]2.查看调度结果
#Pod调度结果为node01两个,node03一个
kubectl get pods -o wide | grep podaffinity-perferred-pod
podaffinity-perferred-pod-7cddc8c964-5tfr2 1/1 Running 0 12m 10.244.5.106 k8s-node03 <none> <none>
podaffinity-perferred-pod-7cddc8c964-kqsmk 1/1 Running 0 12m 10.244.3.109 k8s-node01 <none> <none>
podaffinity-perferred-pod-7cddc8c964-wpqqw 1/1 Running 0 12m 10.244.3.110 k8s-node01 <none> <none>
#以下三个Node都具备标签键为zone,但是这三个Node上没有Pod标签为app=cache及app=db,所以上面的调度策略在选择Pod标签的时候进行退步才得以将Pod调度到Node01和Node03
k8sops@k8s-master01:~/manifests/pod$ kubectl get nodes -l zone -L zone
NAME STATUS ROLES AGE VERSION ZONE
k8s-node01 Ready <none> 28d v1.18.2 beijing
k8s-node02 Ready <none> 28d v1.18.2 shanghai
k8s-node03 Ready <none> 29d v1.18.2 shenzhenPod调度之Pod反亲和性调度
podAntiAffinity介绍
Pod反亲和性podAntiAffinity用于定义Pod对象的亲和约束,Pod反亲和性与Pod亲和性相反,Pod亲和性是将有密切关联的Pod运行到同一平面、同一个区域或者同一台机器上,而反亲和性是将Pod运行在不同区域、不同机器上,Pod反亲和性调度一般用于分散同一类应用的Pod对象等。
podAntiAffinity也被分为硬亲和性和软亲和性,其原理与Node中的硬亲和性及软亲和性一致。
硬亲和性(required):硬亲和性实现的是强制性规则,它是Pod调度时必须要满足的规则,而在不存在满足规则的Node时,Pod对象会被置为Pending状态。
软亲和性(preferred):软亲和性规则实现的是一种柔性调度限制,它倾向于将Pod对象运行于某类特定节点之上,而调度器也将尽量满足此需求,但在无法满足需求时它将退而求其次地选择一个不匹配规则的节点之上。
帮助文档:kubectl explain
pods.spec.affinity.podAntiAffinity
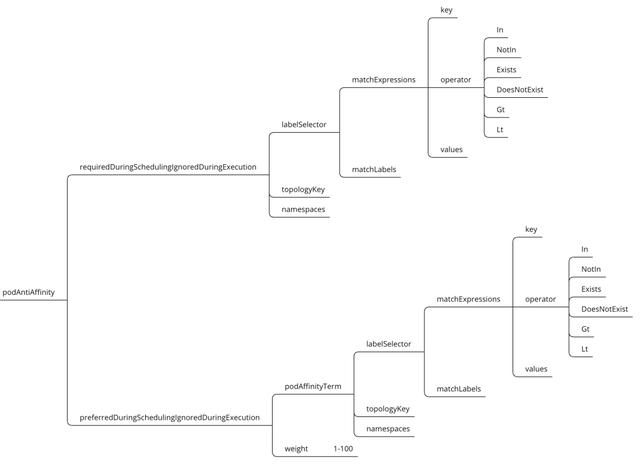
podAntiAffinity示例
1.创建资源配置清单
以下创建了4个Pod,自身标签为app=myapp,使用Pod反亲和的硬亲和性,需要运行在具备标签key为zone的Node上,然后不运行在具备标签为app=myapp的Pod同台Node上,我们下面启动了4个Pod,一共有三个Node,前三个Pod都会被分别调度到不同的三台Node上(因为采用的是反亲和性,还是硬性,所以相同标签的Pod不会调度到同一台Node),最后一个Pod将无家可归,最后无法调度。
cat podAntiAffinity-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podantiaffinity-perferred-pod
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- { key: app, operator: In, values: ["myapp"] }
topologyKey: zone
containers:
- name: myapp
image: busybox:latest
command: ["/bin/sh", "-c", "tail -f /etc/passwd" ]2.创建Pod对象
kubectl apply -f podAntiAffinity-deploy.yaml3.查看调度结果
kubectl get pods -L app -l app=myapp -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP
podantiaffinity-perferred-pod-6576cf75c8-5bw9f 0/1 Pending 0 80s <none> <none> <none> <none> myapp
podantiaffinity-perferred-pod-6576cf75c8-bxp4k 1/1 Running 0 80s 10.244.2.88 k8s-node02 <none> <none> myapp
podantiaffinity-perferred-pod-6576cf75c8-d2fcm 1/1 Running 0 80s 10.244.5.107 k8s-node03 <none> <none> myapp
podantiaffinity-perferred-pod-6576cf75c8-dghr9 1/1 Running 0 80s 10.244.3.111 k8s-node01 <none> <none> myapp4.查看Node标签
kubectl get nodes -L zone -l zone
NAME STATUS ROLES AGE VERSION ZONE
k8s-node01 Ready <none> 28d v1.18.2 beijing
k8s-node02 Ready <none> 28d v1.18.2 shanghai
k8s-node03 Ready <none> 29d v1.18.2 shenzhen
文章来源于网络,侵删!