时序数据库之InfluxDB
最近公司业务重度依赖时序数据库, 公司上个版本选择了OpenTSDB, 在1-2年前,他的确很流行。但是在做软件重构时, 业务层反馈的一些问题, OpenTSDB暂时无法解决,成为了一个痛点, 让我需要考虑其他方案, 由于之前使用过InfluxDB, 也一直在关注, 它给了我惊艳的感觉,所以记忆犹新.
之前做运维时,重度使用过zabbix, 关系型数据库的优化,根本无法解决高IO, 后面又使用过Graphite, 这个安装像迷一样的工具, 它后端在RRD上面设计出了一个简单的时序数据库, 但是配置繁杂,容量完全靠规划。直到使用了InfluxDB, 部署简单,使用方便,高压缩, 对它印象很不错, 但是0.12过后不支持集群。
之前InfluxDB切换了2次存储引擎(它的存储是插件式的), 也没去了解过它切换的原因, 直到看到InfoQ上七牛的演讲从InfluxDB看时序数据的处, 他道出了了原因:
-
LevelDB不支持热备份, influxDB设计的shard会消耗大量文件描述符,将系统资源耗尽。
-
BoltDB解决了热备, 解决了消耗大量文件描述符的问题, 但是引入了一个更致命的问题:容量达到数GB级别时,会产生大量随机写, 造成高IOPS。
-
放弃了他们, 在他们的经验上开始自己实现一个存储引擎: TSM(Time-Structured Merge Tree), 它截取了OpenTSDB的一些设计经验,根据LSM Tree针对时间序列数据进行优化
我认为像这样的针对特殊场景进行优化的数据库会是今后数据库领域发展的主流, 另一个证明就是EleasticSearch一个针对文本解索而设计的数据库, 虽然OpenTSDB也针对时序数据做了优化,但是由于存储系统依然依赖HBase, 所以力度上面感觉没InfluxDB给力。
社区一路走来之艰辛,但是却激情洋溢,他们是先行者. 我对它集群的闭源并不反感, 这群激情洋溢的人需要有商业支持。
这是DB Engine的时序数据库最新的排行榜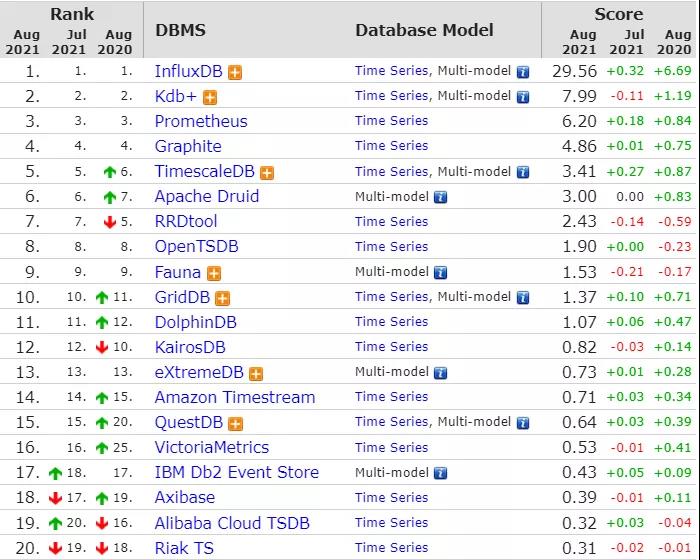

上图可以看出InfluxDB超级火热, 稳居第一,对于一个设计精良,部署简单,使用方便,而且还高性能的时序数据库而言, 想不热都难。
基于Go语言开发,社区非常活跃,项目更新速度很快,日新月异,关注度高, 1.0发布过后, 稳定性也非常高。官方是这样介绍InfluxDB的:
influxdb是一个从底层一步一步成长为能处理高写入,高查询的时序数据库, 它专门针对时序数据做了优化,让其更高性能, 他可以用来存储任何时序数据, 包括DevOps的监控、应用指标、物联网传感器的数据, 并实时分析
这是它github上给出的特性说明:
-
内建HTTP API, 无需自己实现
-
数据高压缩, 支持非常灵活的查询访问
-
支持类SQL查询, 学习成本低, 方便使用
-
安装和管理都十分简单, 数据写入和读取的速度快
-
为实时查询而生, 对每一个点位都建立索引, 及时查询响应速度小于100ms
我们需要一个时序数据库, 他需要能解决我们以下这些问题:
-
一个测试指标多值
一个指标往往有多个维度来描述其变化状态,并不仅仅是值, 比如对于CPU的而言, 应该有中断,负载, 使用率等。
2.多Tag支持
tag是对一个指标的描述,是一个标签, 在业务上Tag对于分组过滤非常有意义, 用于标示一个指标在业务上的意义, 比如对于IOT来说, 传感器的指标往往是一个无意义的id, 因此需求给它打上name标签, 标示他的特殊意义, 打上设备ID, 标示它属于哪个设备, 打上位置标签, 标示该指标来源于哪个地方。
3.在指标的值上能做一些基本的比较运算
作为一个数据库,在功能层面需要解决一些基本的运算, 比如求和,求最小,求最大, 但这还不够, 需要支持条件过滤, 支持Tag的条件过滤, 支持值的条件过滤, 支持值的条件过滤是关键, 不然会产生巨大的数据复制, 比如我们需要过滤出 CPU > 90的机器, 如果数据库不支持, 那么我需要将这些数据从数据库中查出来,复制给我的程序处理。
这带来了巨大的问题:
-
数据库要吐出如此大量的数据, 负载升高, 出口流量暴增
-
程序拿到如此大量的数据, 给处理方带来了巨大的计算压力, 如果前段采用Angular或者React来写, 一个运行在pc上的小小的浏览器,根本处理不了。
-
处理效率低,数据的处理本该在数据存储的地方进行, 比如Hadoop, 完全没必要复制。
4.指标计算的中间结果需要存会指标
这是一个比较常见的场景, 使用RDD时更是常用,比如数据是按照30秒存储的,但是我需要 这样一个聚合维度 5m, 15m, 1h, 3h, 12h, 然后我平时只使用这些维度的数据, 不用每次临时计算。
influxDB的核心概念包含: Line Protocol, Retention Policy, Series, Point, Continuous Query.
5.1 Line Protocol
Line Protocol用于描述存入数据库的数据格式, 也可以说是数据协议, 相比于JSON格式,Line Protocol无需序列化,更加高效, 官方对它做了全面的介绍Line Protocol, 下面摘取语法部分做简要说明:Line Protocol里面的一行就是InfluxDB里面的一个点位, 他将一个点分割成measurement, tag_set, field_set, timestamp4个部分, 例如: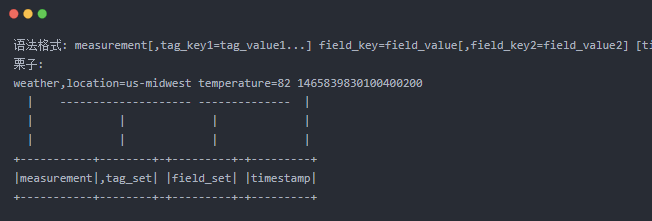
-
measurement: metric name, 需要监控的指标的名称, 比如上面的weather
-
tag_set: 使用”,”与measurement隔开, 表示一组Tag的集合, 用于保存点位的元数据, 为可选项, 会进行索引,方便查询时用于过滤条件, 格式: =,=, 比如上面的location=us-midwest
-
field_set: 使用空格与tag_set隔开, 标示一组Field的集合, 用于保存该点位多维度的值, 支持各种类型,数据存储时不会进行索引,格式: =,=, 比如上面的temperature=82
-
timestamp: 采集该点位的时间戳, 时间的默认精度是纳秒.
存储策略:measurements,tag keys,field keys,tag values全局存一份。field values和timestamps每条数据存一份。
5.2 Retention Policy
指数据的保存策略, 包含数据的保存时间和副本数(集群中的概念),默认保存时间是永久,副本是1个, 但是我们可以修改, 也可以创建新的保存策略
5.3 Series
InfluxDB中元数据的数据结构体, series相当于是InfluxDB中元数据的集合,在同一个database中,retention policy、measurement、tag sets完全相同的数据同属于一个series,同一个series的数据在物理上会按照时间顺序排列存储在一起。
series 的key为 measurement+所有tags的序列化字符串, 他保存着该series的Retention policy, Measurement,Tag set, 比如: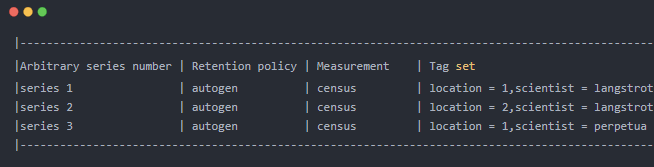
5.4 Point
InfluxDB中单条插入语句的数据结构体, 用于保存点位的值的集合, 每一个Point通过series和timestamp进行唯一标示:
5.5 Schema
用于描述数据在InfluxDB的组织形式, InfluxDB的Schema十分简单由 这些概念组成:
-
databases
-
retention policies
-
series
-
measurements
-
tag keys
-
tag values
-
field keys
在操作数据库的时候,需要知道这些概念。
5.6 Continuous Query
简称CQ, 是预先配置好的一些查询命令,SELECT语句必须包含GROUP BY time(),influxdb会定期自动执行这些命令并将查询结果写入指定的另外的measurement中。
利用这个特性并结合RP我们可以方便地保存不同粒度的数据,根据数据粒度的不同设置不同的保存时间,这样不仅节约了存储空间,而且加速了时间间隔较长的数据查询效率,避免查询时再进行聚合计算。
5.7 存储引擎
从LevelDB(LSM Tree),到BoltD(mmap B+树),现在是自己实现的TSM Tree的算法,类似LSM Tree,针对InfluxDB的使用做了特殊优化。
5.7.1 Shard
Shard这个概念并不对普通用户开放,Shard也不是存储引擎, 它在存储引擎之上的一个概念, 存储引擎负责存储shard, 因此在讲存储引擎之前先讲明shard。
在InfluxDB中按照数据的时间戳所在的范围,会去创建不同的shard,每一个shard都有自己的存储引擎相关文件,这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
它和retention policy相关联。每一个存储策略下会存在许多shard,每一个shard存储一个指定时间段内的数据,并且不重复,例如7点-8点的数据落入shard0 中,8点-9点的数据则落入shard1中。每一个shard都对应一个底层的存储引擎。
当检测到一个shard中的数据过期后,只需要将这个shard的资源释放,相关文件删除即可,这样的做法使得删除过期数据变得非常高效。
5.7.2 LevelDB
5.7.3 BoltDB
5.7.4 TSM Tree
6.1 安装与部署
我这里主要做功能测试, 后面会有机会专门做性能测试, 因此这里使用官方提供的docker镜像部署,官方镜像最新也是1.2版本
配置Daocloud的镜像加速源或者阿里的加速源,然后直接拉取镜像

由于influxDB开发时就设计好了, 官方也给出了环境配置变量,启动时可以通过这些环境变量对influxdb进行配置InfluxDB配置
6.2 函数与SQL
内部提供很多函数,方便一些基本操作InfluxQL Functions
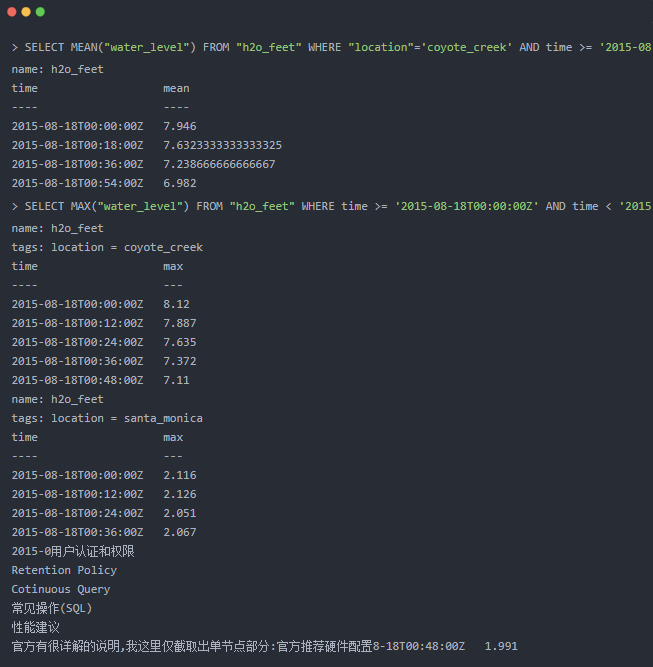
6.3 用户认证和权限
6.4 Retention Policy
6.5 Cotinuous Query
6.6 常见操作(SQL)
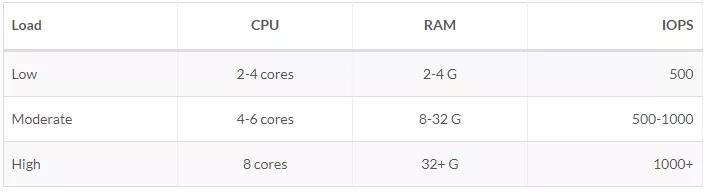
官方有很详解的说明,我这里仅截取出单节点部分:官方推荐硬件配置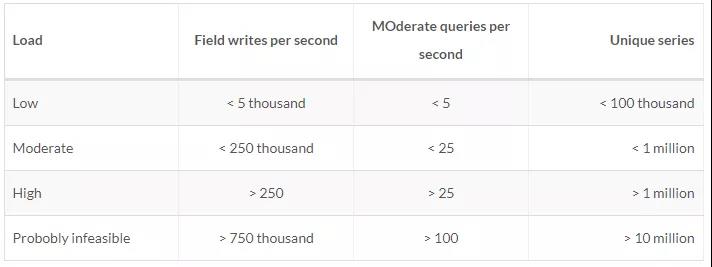
根据负载情况官方推荐的硬件需求: