

Python 多线程居然是 —— 假的?
最近有位读者提问:
Python 的多线程真是假的吗?
一下子点到了 Python 长期被人们喜忧参半的特性 —— GIL 上了。
到底是怎么回事呢?今天我们来聊一聊。
十全十美
我们知道 Python 之所以灵活和强大,是因为它是一个解释性语言,边解释边执行,实现这种特性的标准实现叫作 CPython。
它分两步来运行 Python 程序:
-
首先解析源代码文本,并将其编译为字节码(bytecode)[1] -
然后采用基于栈的解释器来运行字节码 -
不断循环这个过程,直到程序结束或者被终止
灵活性有了,但是为了保证程序执行的稳定性,也付出了巨大的代价:
引入了 全局解释器锁 GIL(global interpreter lock)[2]
以保证同一时间只有一个字节码在运行,这样就不会因为没用事先编译,而引发资源争夺和状态混乱的问题了。
看似 “十全十美” ,但,这样做,就意味着多线程执行时,会被 GIL 变为单线程,无法充分利用硬件资源。
来看代码:
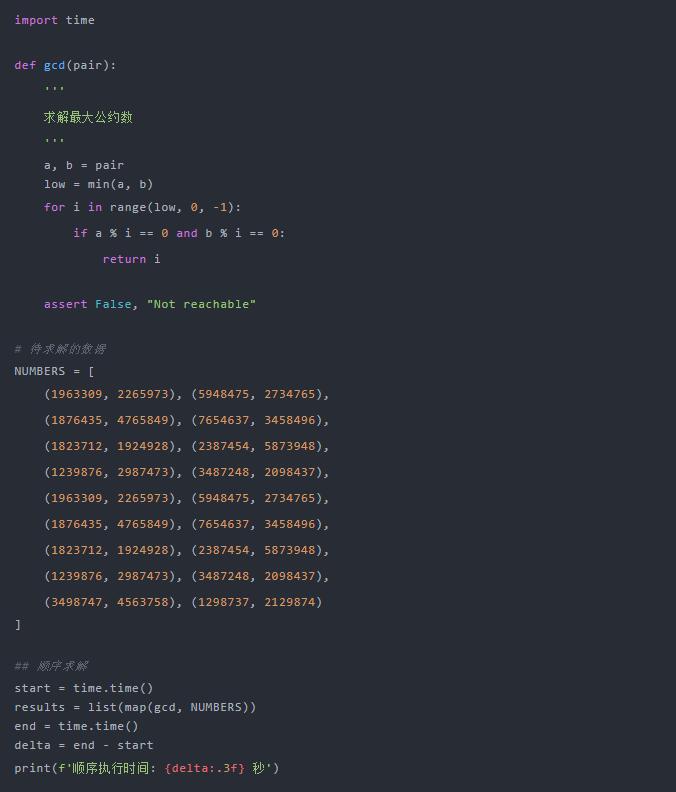

-
函数 gcd用于求解最大公约数,用来模拟一个数据操作 -
NUMBERS为待求解的数据 -
求解方式利用 map方法,传入处理函数 gcd, 和待求解数据,将返回一个结果数列,最后转化为list -
将执行过程的耗时计算并打印出来
在笔者的电脑上(4核,16G)执行时间为 2.043 秒。
如何换成多线程呢?
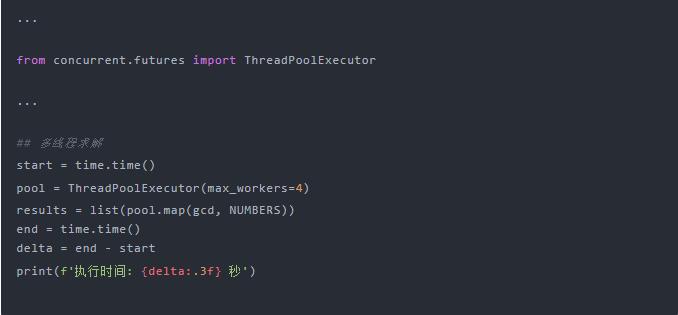
-
这里引入了 concurrent.futures模块中的线程池,用线程池实现起来比较方便 -
设置线程池为 4,主要是为了和 CPU 的核数匹配 -
线程池 pool提供了多线程版的map,所以参数不变
看看运行效果:


并行执行的时间竟然更长了!
连续执行多次,结果都是一样的,也就是说在 GIL 的限制下,多线程是无效的,而且因为线程调度还多损耗了些时间。
戴着镣铐跳舞
难道 Python 里的多线程真的没用吗?
其实也并不是,虽然了因为 GIL,无法实现真正意义上的多线程,但,多线程机制,还是为我们提供了两个重要的特性。
一:多线程写法可以让某些程序更好写
怎么理解呢?
如果要解决一个需要同时维护多种状态的程序,用单线程是实现是很困难的。
比如要检索一个文本文件中的数据,为了提高检索效率,可以将文件分成小段的来处理,最先在那段中找到了,就结束处理过程。
用单线程的话,很难实现同时兼顾多个分段的情况,只能顺序,或者用二分法执行检索任务。
而采用多线程,可以将每个分段交给每个线程,会轮流执行,相当于同时推荐检索任务,处理起来,效率会比顺序查找大大提高。
二:处理阻塞型 I/O 任务效率更高
阻塞型 I/O 的意思是,当系统需要与文件系统(也包括网络和终端显示)交互时,由于文件系统相比于 CPU 的处理速度慢得多,所以程序会被设置为阻塞状态,即,不再被分配计算资源。
直到文件系统的结果返回,才会被激活,将有机会再次被分配计算资源。
也就是说,处于阻塞状态的程序,会一直等着。
那么如果一个程序是需要不断地从文件系统读取数据,处理后在写入,单线程的话就需要等等读取后,才能处理,等待处理完才能写入,于是处理过程就成了一个个的等待。
而用多线程,当一个处理过程被阻塞之后,就会立即被 GIL 切走,将计算资源分配给其他可以执行的过程,从而提示执行效率。
有了这两个特性,就说明 Python 的多线程并非一无是处,如果能根据情况编写好,效率会大大提高,只不过对于计算密集型的任务,多线程特性爱莫能助。
曲线救国
那么有没有办法,真正的利用计算资源,而不受 GIL 的束缚呢?
当然有,而且还不止一个。
先介绍一个简单易用的方式。
回顾下前面的计算最大公约数的程序,我们用了线程池来处理,不过没用效果,而且比不用更糟糕。
这是因为这个程序是计算密集型的,主要依赖于 CPU,显然会受到 GIL 的约束。
现在我们将程序稍作修改:
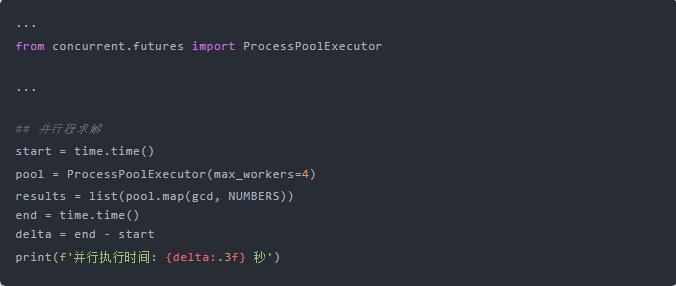
看看效果:

并行执行提升了将近 3 倍!什么情况?
仔细看下,主要是将多线程中的 ThreadPoolExecutor 换成了 ProcessPoolExecutor,即进程池执行器。
在同一个进程里的 Python 程序,会受到 GIL 的限制,但不同的进程之间就不会了,因为每个进程中的 GIL 是独立的。
是不是很神奇?这里,多亏了 concurrent.futures 模块将实现进程池的复杂度封装起来了,留给我们简洁优雅的接口。
这里需要注意的是,ProcessPoolExecutor 并非万能的,它比较适合于 数据关联性低,且是 计算密集型 的场景。
如果数据关联性强,就会出现进程间 “通信” 的情况,可能使好不容易换来的性能提升化为乌有。
处理进程池,还有什么方法呢?那就是:
用 C 语言重写一遍需要提升性能的部分
不要惊愕,Python 里已经留好了针对 C 扩展的 API。
但这样做需要付出更多的代价,为此还可以借助于 SWIG[3] 以及 CLIF[4] 等工具,将 python 代码转为 C。
有兴趣的读者可以研究一下。
自强不息
了解到 Python 多线程的问题和解决方案,对于钟爱 Python 的我们,何去何从呢?
有句话用在这里很合适:
求人不如求己
哪怕再怎么厉害的工具或者武器,都无法解决所有的问题,而问题之所以能被解决,主要是因为我们的主观能动性。
对情况进行分析判断,选择合适的解决方案,不就是需要我们做的么?
对于 Python 中 多线程的诟病,我们更多的是看到它阳光和美的一面,而对于需要提升速度的地方,采取合适的方式。这里简单总结一下:
-
I/O 密集型的任务,采用 Python 的多线程完全没用问题,可以大幅度提高执行效率 -
对于计算密集型任务,要看数据依赖性是否低,如果低,采用 ProcessPoolExecutor代替多线程处理,可以充分利用硬件资源 -
如果数据依赖性高,可以考虑将关键的地方改用 C 来实现,一方面 C 本身比 Python 更快,另一方面,C 可以之间使用更底层的多线程机制,而完全不用担心受 GIL 的影响 -
大部分情况下,对于只能用多线程处理的任务,不用太多考虑,之间利用 Python 的多线程机制就好了,不用考虑太多
总结
没用十全十美的解决方案,如果有,也只能是在某个具体的条件之下,就像软件工程中,没用银弹一样。
面对真实的世界,只有我们自己是可以依靠的,我们通过学习了解更多,通过实践,感受更多,通过总结复盘,收获更多,通过思考反思,解决更多。这就是我们人类不断发展前行的原动力。
为了我们美好的明天,为了人类美好的明天,加油!
比心!