

这篇监控系统的建设思路,让你彻底找出性能瓶颈
一、起始
二、系统监控
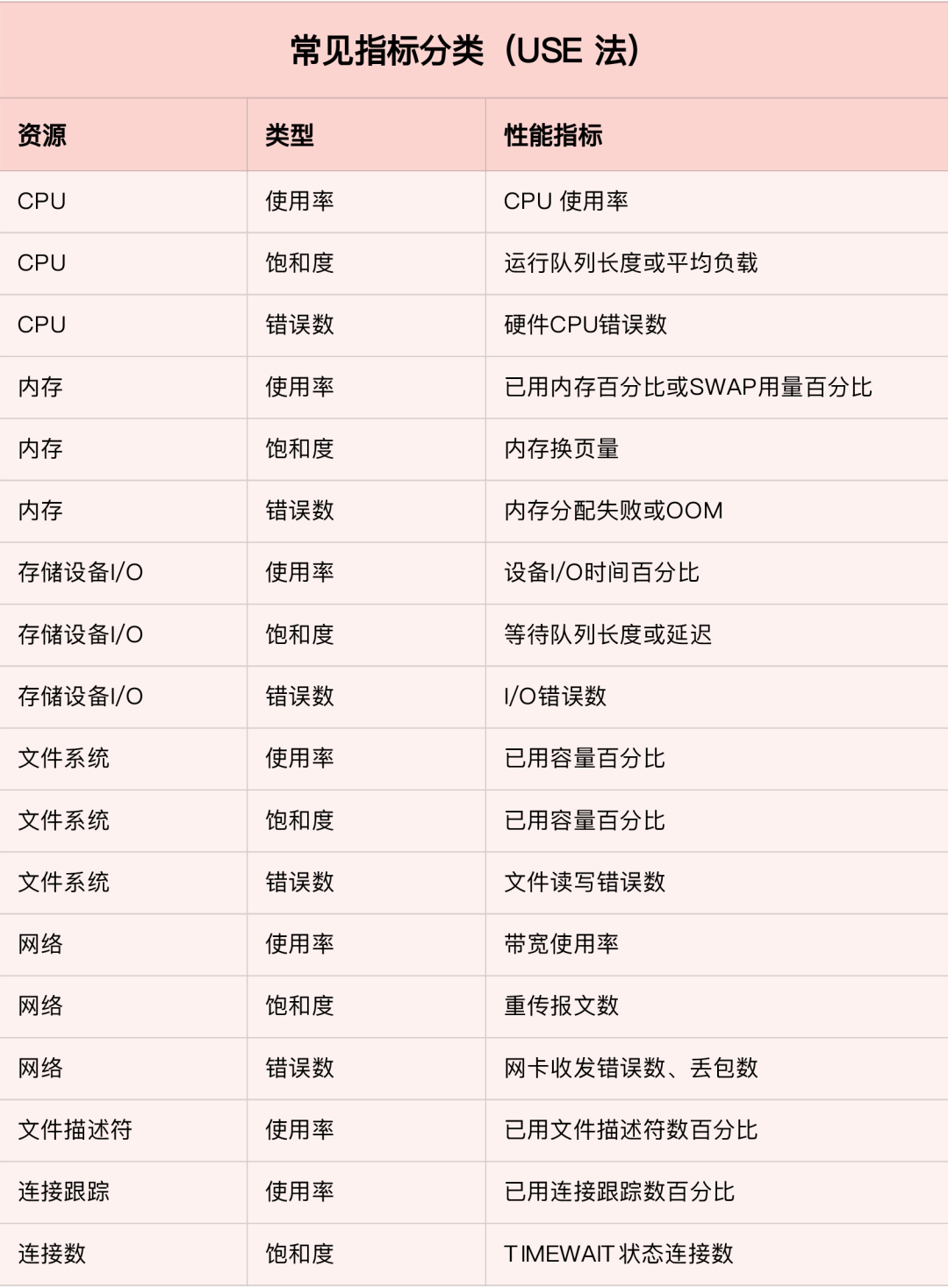
1、USE 法
-
使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时间都用于服务。 -
饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受更多的请求。 -
错误数表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
2、性能指标

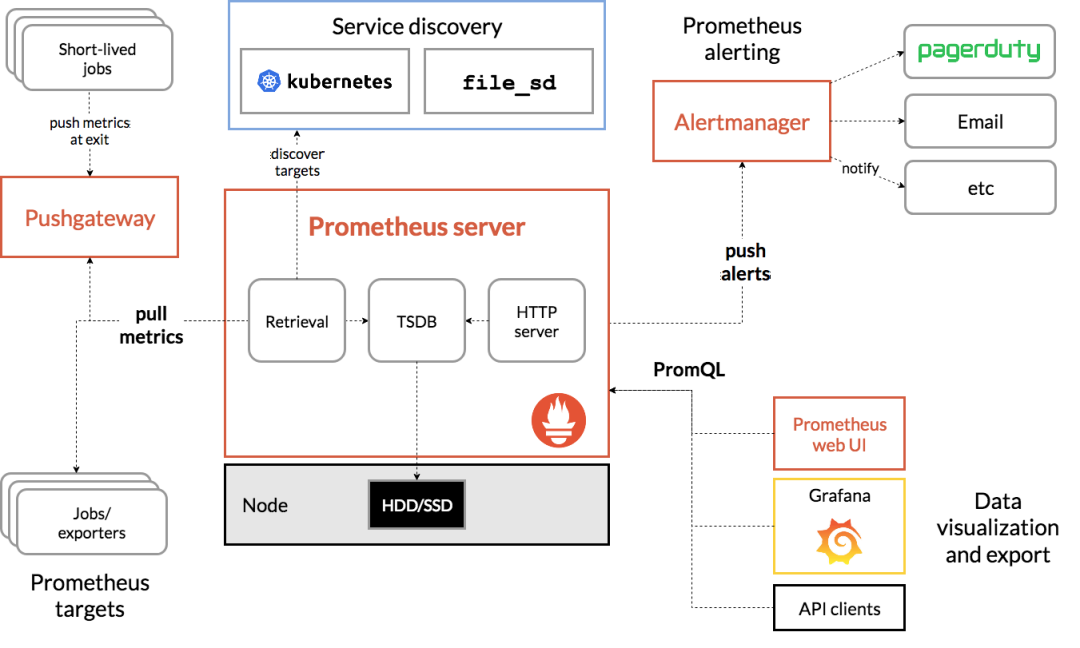
3、监控系统
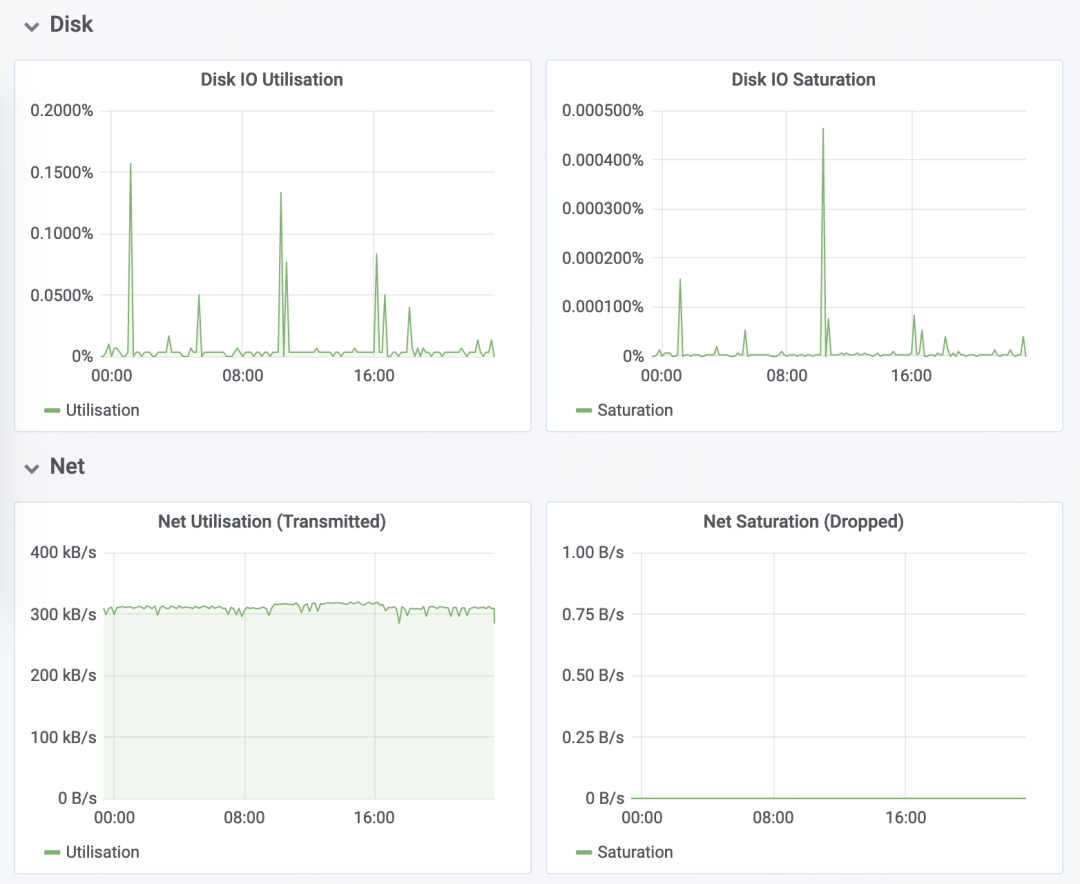
4、最后总结
三、应用监控
1、应用监控指标
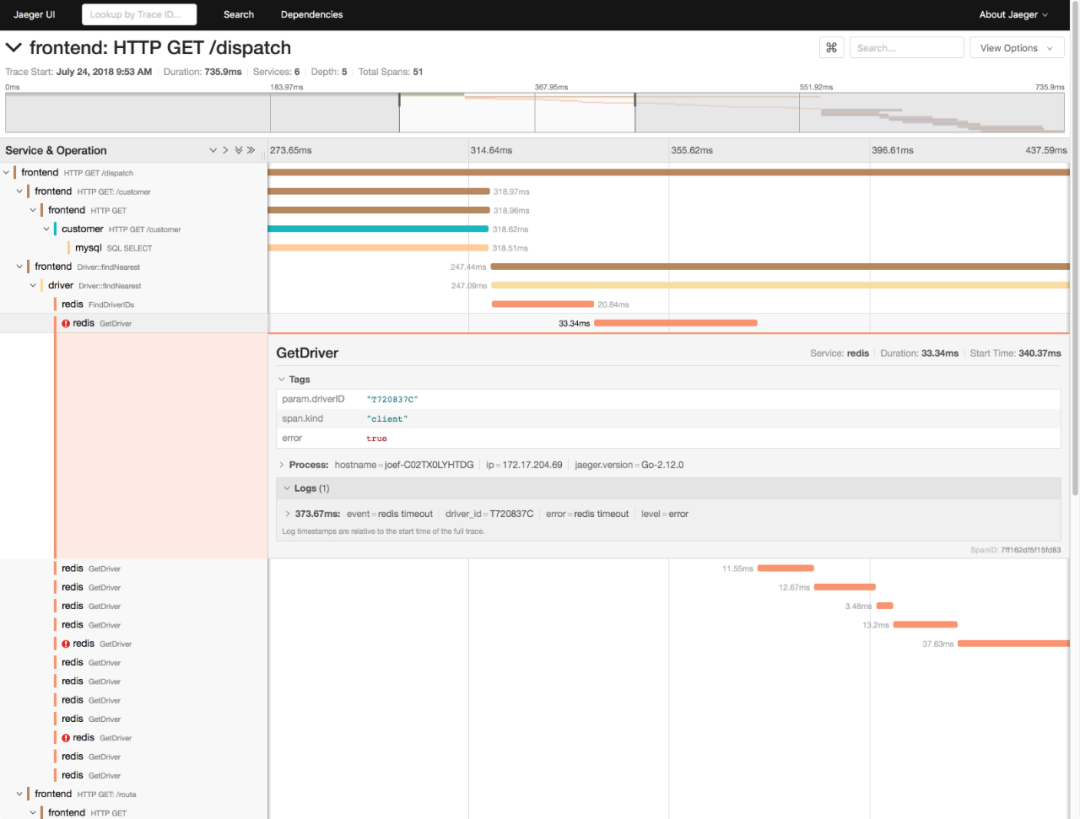
2、全链路监控
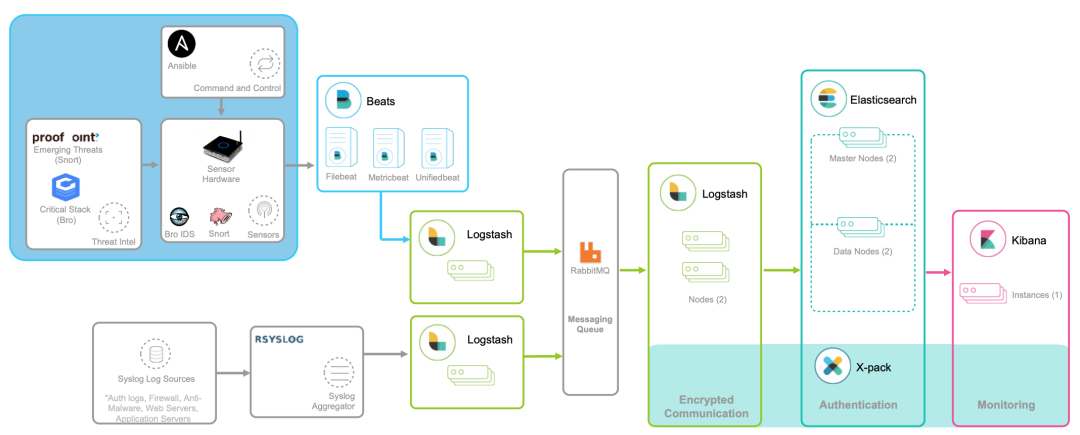
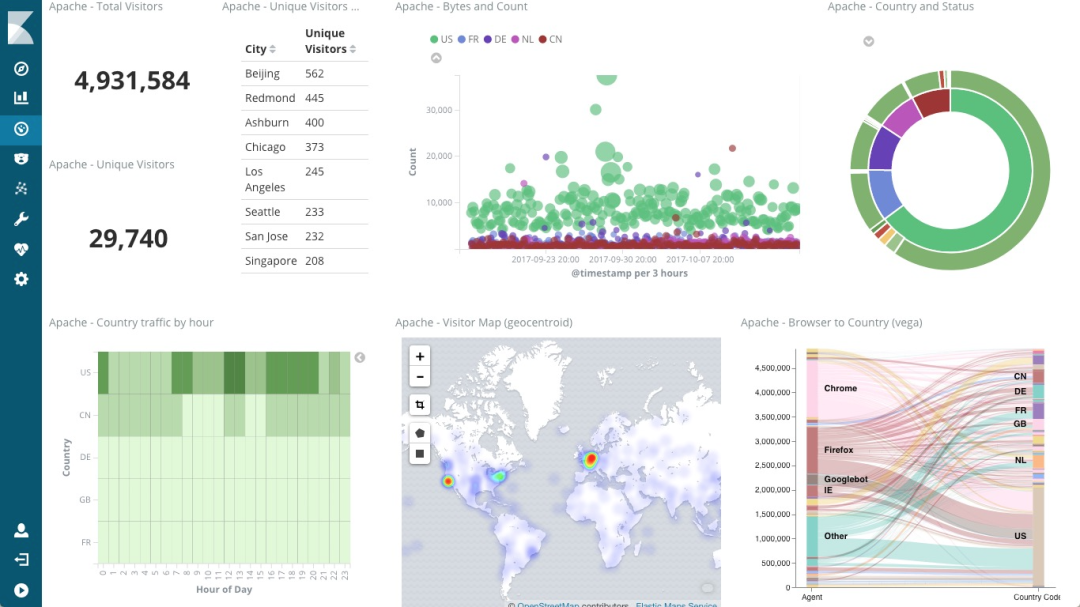
3、日志监控
四、最后总结
作者:-零
链接:https://www.cnblogs.com/-wenli/p/14017850.html