

linux教程 | 如何在 Linux Web 服务器上快速跟踪 PDF 访问
是否可以跟踪您网站的用户点击下载 PDF 或 JPG 等二进制文件的次数?对的,这是可能的。这简单吗?我原本不这么认为。我错了。
这个故事开始于我在我的Bootstrap IT 网站上优化我的新书的登陆页面,保持最新:你不能错过的所有重大技术趋势的背景资料。
我想提供对本书示例章节的 PDF 文件的访问。但我也想知道有多少人实际下载了它。
现在让我们退后一步。Google Analytics是一项免费服务,它使用插入到您的 HTML 文件中的代码片段来收集和显示有关您的文件被访问频率的数据。
Google Analytics 的魔力和问题在于可以透露多少有关用户的信息。我在 Keeping Up 书中讨论了与该服务相关的一些隐私问题。我还提到了我自己在自己的网站上使用该服务时至少感到有点内疚。
无论如何,谷歌分析本身并不能告诉你很多关于你的基于网络的 PDF 是如何被使用的。当然,有一些技巧可以解决这个问题。
传统方法包括设置Google 跟踪代码管理器、自定义您使用的请求 URL 的语法,或者,如果您的网站使用 WordPress 软件,则使用Monster Insights 插件。这些都可以工作,但需要相当陡峭的学习曲线。
但我是 Linux 系统管理员。而且,正如我经常提醒我周围的人一样,最好的系统管理员是懒惰的。学习曲线?这听起来有点像工作。不会发生在我的手表上。
所以这是交易。显然,我的 Web 服务器运行 Linux。而且,在底层,HTTP 流量由 Apache 处理。这意味着在我的网站上发生的所有事情都将由 Apache 记录。
一切。只需要从我的本地工作站运行一行 Bash,就可以让我了解我的 PDF 示例章节的内容:
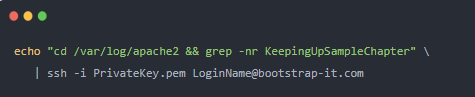

让我们分解一下。引号 ( cd /var/log/apache2) 中的两个命令中的第一个会将我们移动到 Linux 服务器上的 /var/log/apache2/ 目录,Apache 将在该目录中写入其日志。那不是火箭科学。
该目录中将有多个感兴趣的文件。这是因为与常规访问和错误相关的消息被保存到不同的文件中,并且因为文件轮换策略意味着这些文件中的任何一个都可能有多个版本。因此,我将使用grep在所有未压缩文件中搜索该KeepingUpSampleChapter字符串。KeepingUpSampleChapter当然,它是 PDF 文件名的一部分。
然后我将该命令通过管道传输到 SSH,SSH 将连接到我的远程服务器并执行该命令。这是成功运行后单个条目的外观(出于隐私考虑,我删除了请求者的 IP 地址):
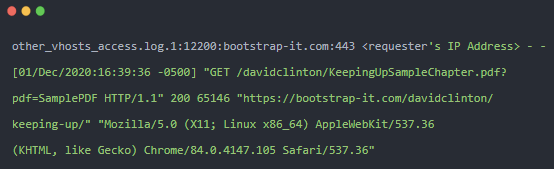
我们可以看到:
- 出现条目的日志文件 (
other_vhosts_access.log.1) - 请求者的 IP 地址(已编辑)
- 时间戳告诉我们文件被访问的确切时间
- 文件在服务器文件系统上的相对位置 (
/davidclinton/KeepingUpSampleChapter.pdf) - 发出请求的 URL (
https://bootstrap-it.com/davidclinton/keeping-up/) - 以及用户正在运行的浏览器
这是很多信息。如果我们只是想知道文件被下载了多少次,我们可以简单地将输出通过管道传递给wc命令,该命令将告诉我们关于输出的三件事:行数、单词数和包含的字符数。该命令如下所示:

这种方法有一个可能的限制。如果您的网站很忙,日志文件会频繁翻转,通常一天超过一次。默认情况下,第一次翻转后,文件使用gz算法压缩,无法读取grep。
该zgrep命令处理此类文件不会有任何问题,但该过程最终可能需要很长时间。您可能会考虑编写一个简单的自定义脚本来解压缩每个gz文件,然后grep对其内容进行常规运行。那将是你的项目。
在我的bootstrap-it.com上以书籍、课程和文章的形式提供了更多的管理优势。
原文:https://www.freecodecamp.org/news/quickly-track-pdf-access-linux-web-server/