

分享一款懒人必备的Python爬虫神器

pip install pytest-playwrightplaywright install
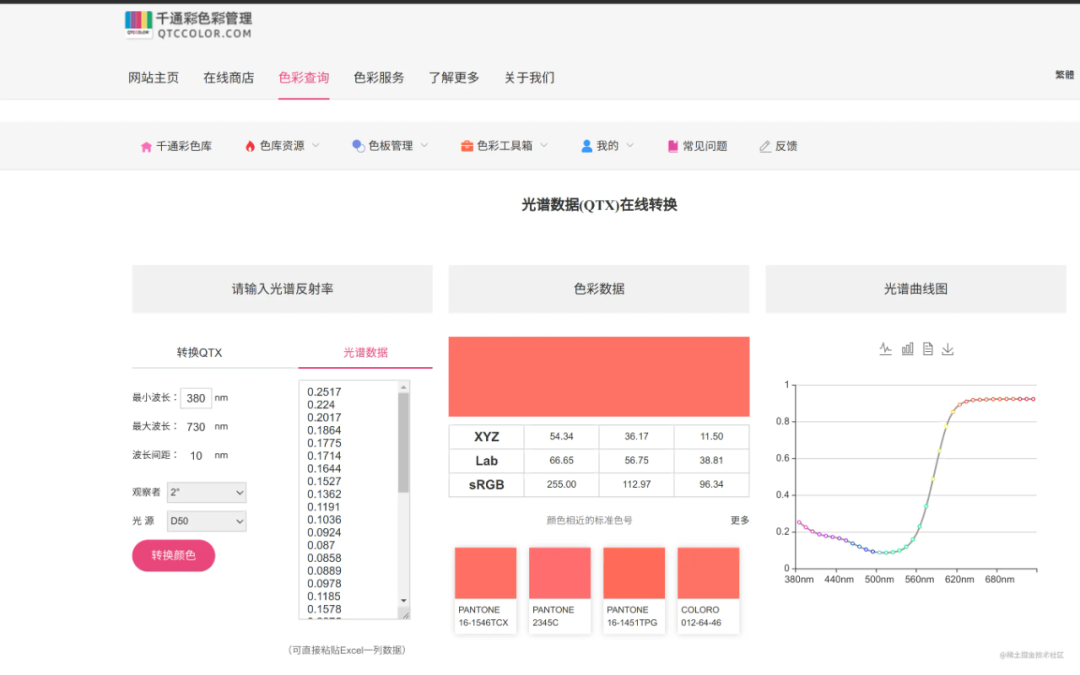
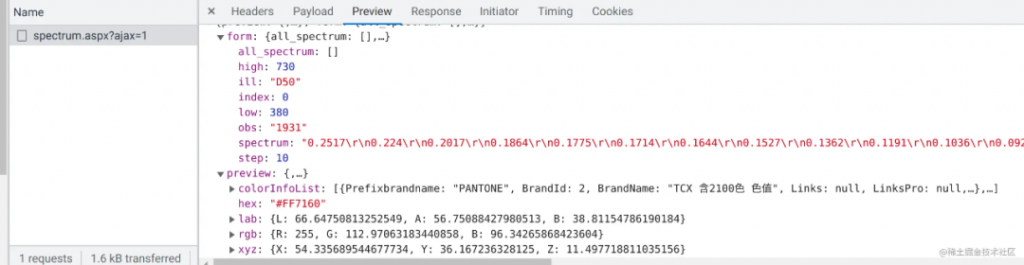
python -m playwright codegen xxx.com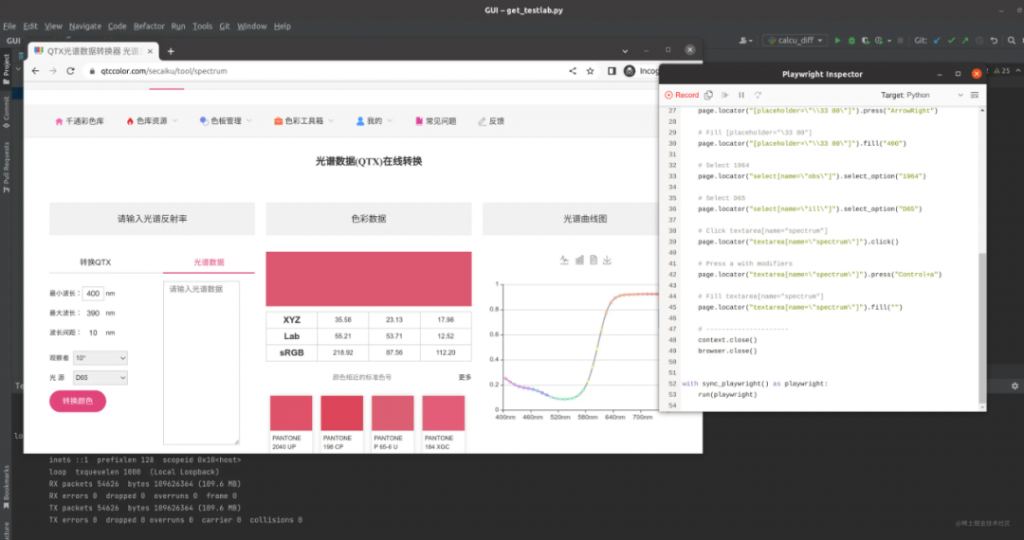
import timefrom playwright.sync_api import Playwright, sync_playwright, expectimport numpy as npdata_test=np.loadtxt('./dist/1_res.csv',delimiter=',')def get_str(arr):arr_str=""for i in arr:arr_str+=str(format(i,".2f"))+"\r\n"return arr_strlabs=[]def run(playwright: Playwright) -> None:browser = playwright.chromium.launch(headless=False)context = browser.new_context()# Open new pagepage = context.new_page()# Go to https://www.qtccolor.com/secaiku/tool/spectrumpage.goto("https://www.qtccolor.com/secaiku/tool/spectrum")# Click div[role="tab"]:has-text("光谱数据")page.locator("div[role=\"tab\"]:has-text(\"光谱数据\")").click()# Click text=最小波长:nmpage.locator("text=最小波长:nm").click()# Fill [placeholder="\33 80"]page.locator("[placeholder=\"\\33 80\"]").fill("400")# Select 1964page.locator("select[name=\"obs\"]").select_option("1964")# Select D65page.locator("select[name=\"ill\"]").select_option("D65")# Fill textarea[name="spectrum"]for i in range(len(data_test)):inputs=get_str(data_test[i,:])# Click textarea[name="spectrum"]page.locator("textarea[name=\"spectrum\"]").click()page.locator("textarea[name=\"spectrum\"]").press("Control+a")page.locator("textarea[name=\"spectrum\"]").fill(inputs)# Click button:has-text("转换颜色")page.locator("button:has-text(\"转换颜色\")").click()time.sleep(1)# Click text=Lab0.000.000.00 >> td >> nth=1L=float(page.locator('xpath=//*[@id="scroll_container"]/div[1]/div/div[2]/table/tbody/tr[2]/td[2]').inner_text())# Click text=Lab0.000.000.00 >> td >> nth=2a=float(page.locator('xpath=//*[@id="scroll_container"]/div[1]/div/div[2]/table/tbody/tr[2]/td[3]').inner_text())# Click text=Lab0.000.000.00 >> td >> nth=3b=float(page.locator('xpath=//*[@id="scroll_container"]/div[1]/div/div[2]/table/tbody/tr[2]/td[4]').inner_text())print(L,a,b)labs.append([L,a,b])# ---------------------context.close()browser.close()with sync_playwright() as playwright:run(playwright)np.savetxt('./1_lab_res.csv',labs,delimiter=",")
大厂出品果然不同,使用它在不考虑运行效率(有异步但是我懒得看了)的情况下可以轻松实现复杂操作,懒人最爱!
来源:https://juejin.cn/post/7140542063061237773(侵删)